[파이썬] 그룹별로 분석하기

Groupby
데이터를 불러온다.
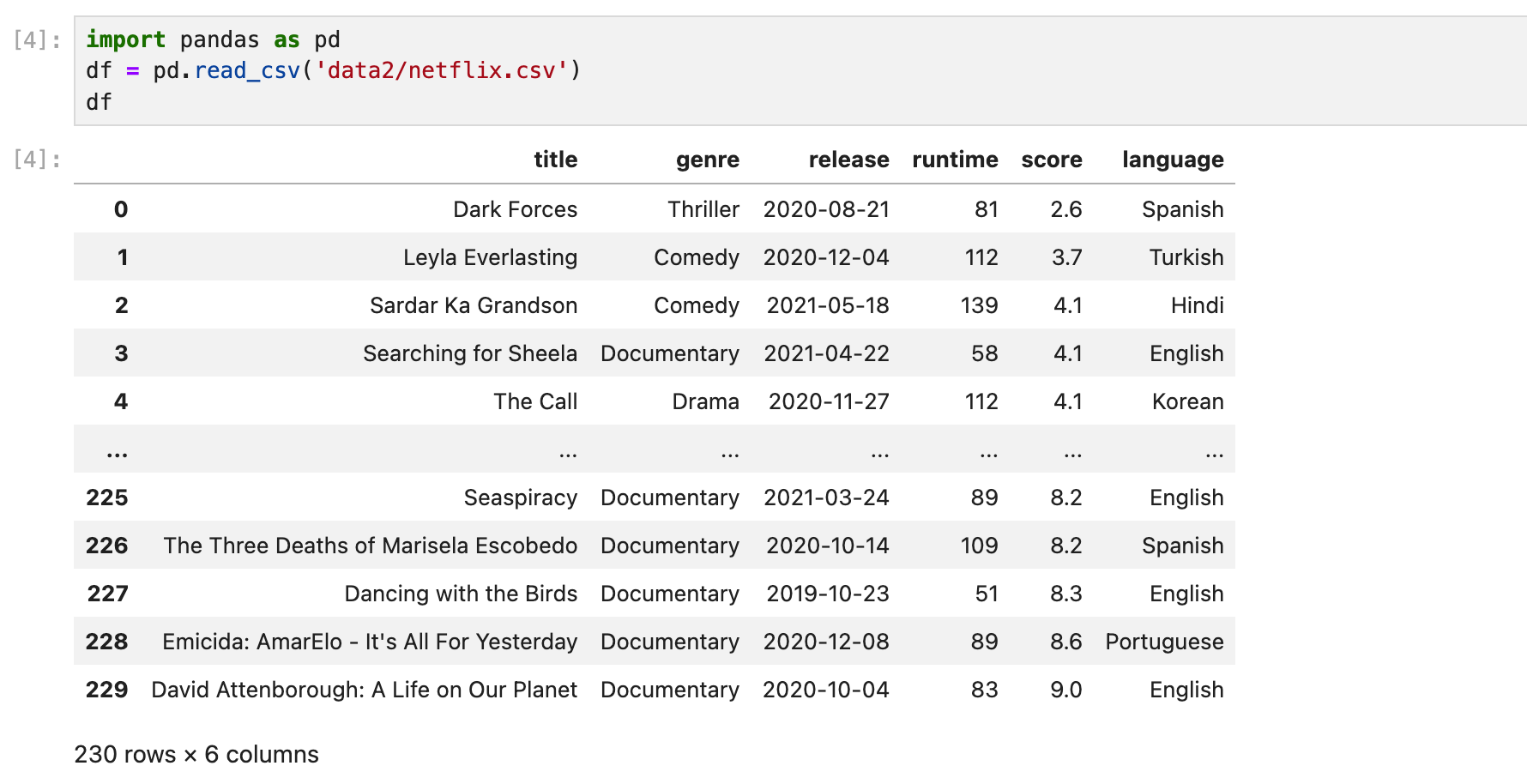
정보들을 본다. 결측값은 없다.

groupby()
장르를 기준으로 그룹으로 묶어준다.

count()
함수를 사용하면 결과를 데이터프레임으로 보여준다.

size()
함수를 사용하면 결과를 시리즈로 보여준다.

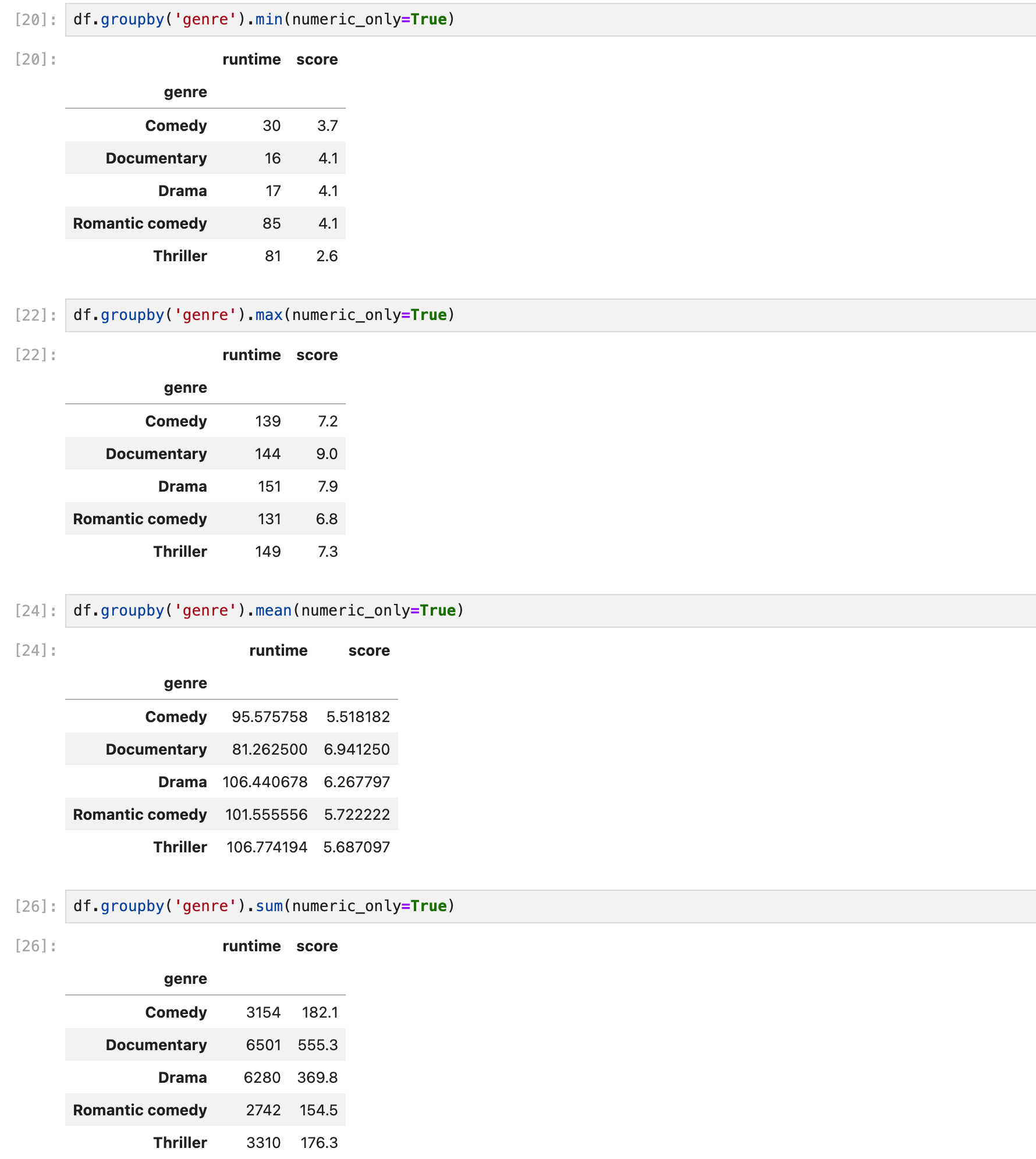
최소, 최대, 평균, 합계 모두 구할 수 있다.
numeric_only는 숫자만 보여주는 파라미터이다.
지금까지 런타임과 스코어가 같이 나왔는데 스코어만 보고 싶다면 []를 이용한다.
물론 [] 안에 리스트처럼 여러 컬럼명을 넣을수도 있다.

실습
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
# 여기에 코드를 작성하세요.
olympic_df.groupby('sport')['height', 'weight'].mean()
category 데이터 타입 다루기

import pandas as pd
clothes_df = pd.DataFrame({
'size': ['L', 'S', 'XS', 'L', 'S', 'XL', 'L', 'S', 'M', 'XS',
'M', 'M', 'XS', 'L', 'XL', 'XS', 'M', 'S', 'L', 'XL'],
'sales': [130, 200, 120, 120, 140, 160, 190, 90, 110, 100,
150, 180, 100, 200, 80, 140, 150, 90, 80, 130]
})
clothes_df


pd.Categorical(clothes_df['size'], ordered=True, categories=['XS', 'S', 'M', 'L', 'XL'])['L', 'S', 'XS', 'L', 'S', ..., 'XS', 'M', 'S', 'L', 'XL']
Length: 20
Categories (5, object): ['XS' < 'S' < 'M' < 'L' < 'XL']그리고 size 컬럼에 이 값들을 다시 저장해줄게요.
clothes_df['size'] = pd.Categorical(
clothes_df['size'],
ordered=True,
categories=['XS', 'S', 'M', 'L', 'XL']
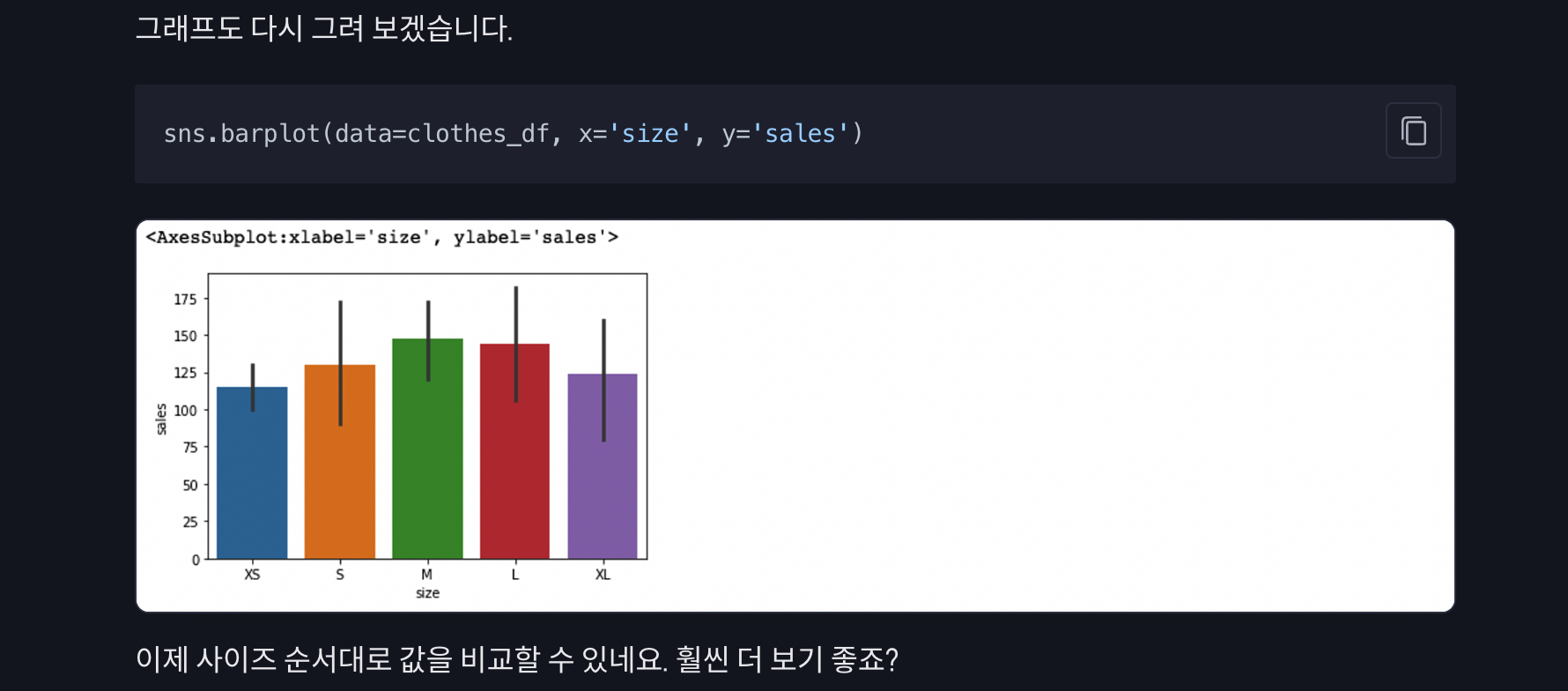
)이제 size컬럼을 기준으로 데이터프레임을 다시 오름차순 정렬해서 보겠습니다.
clothes_df.sort_values(by='size')
Groupby와 멀티 인덱스
기본 데이터를 불러온다.

장르와 연도를 기준으로 그룹을 만들어 분석하고 싶다.
개봉일의 타입을 데이트타임으로 바꿔서 연도 정보를 저장해준다.

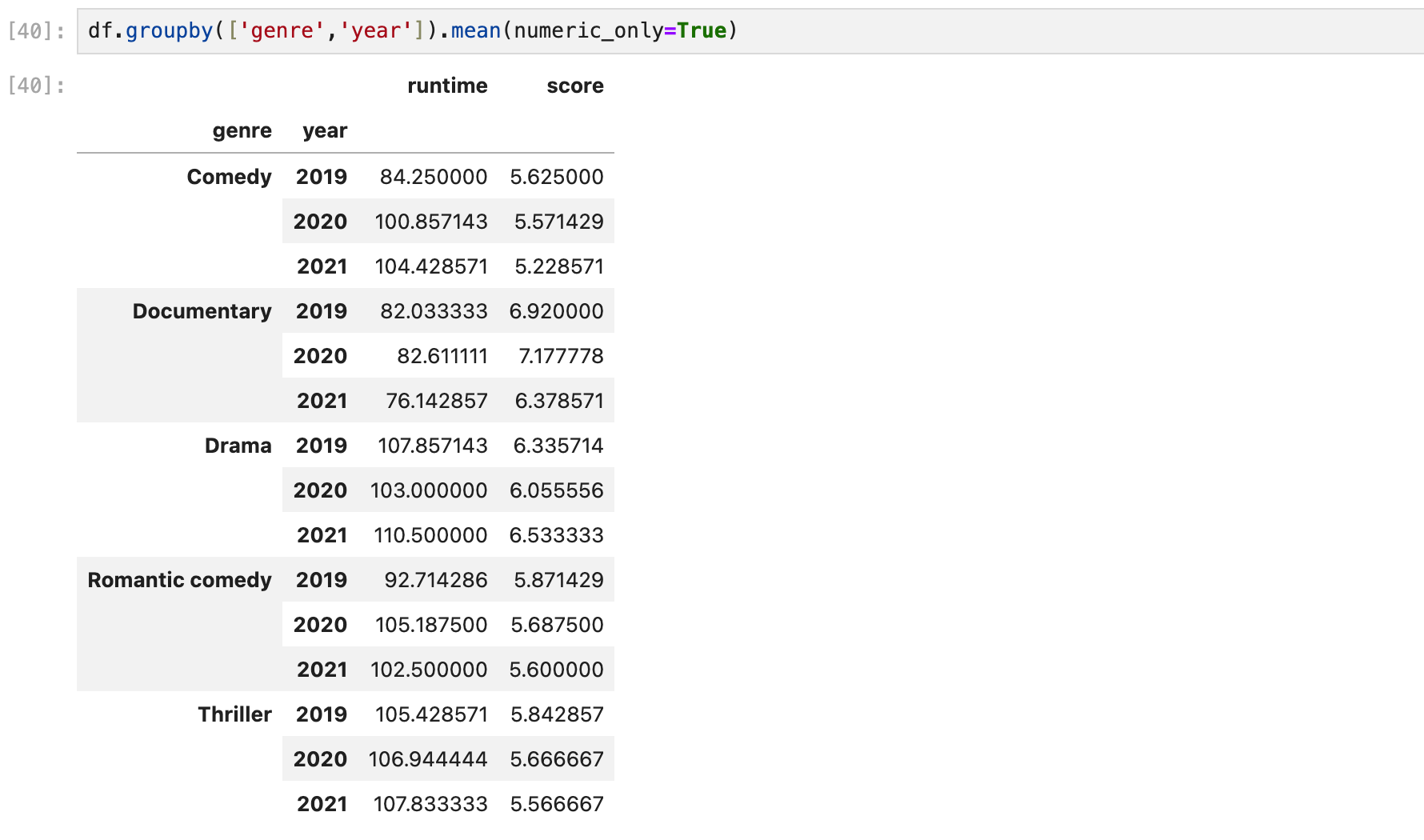
장르와 연도를 그룹으로 묶어서 평균을 본다.
그러면 인덱스가 두개가 있는 것을 볼 수 있다.
이때 연도와 장르의 순서를 바꾸면 인덱스의 순서도 바뀐다.

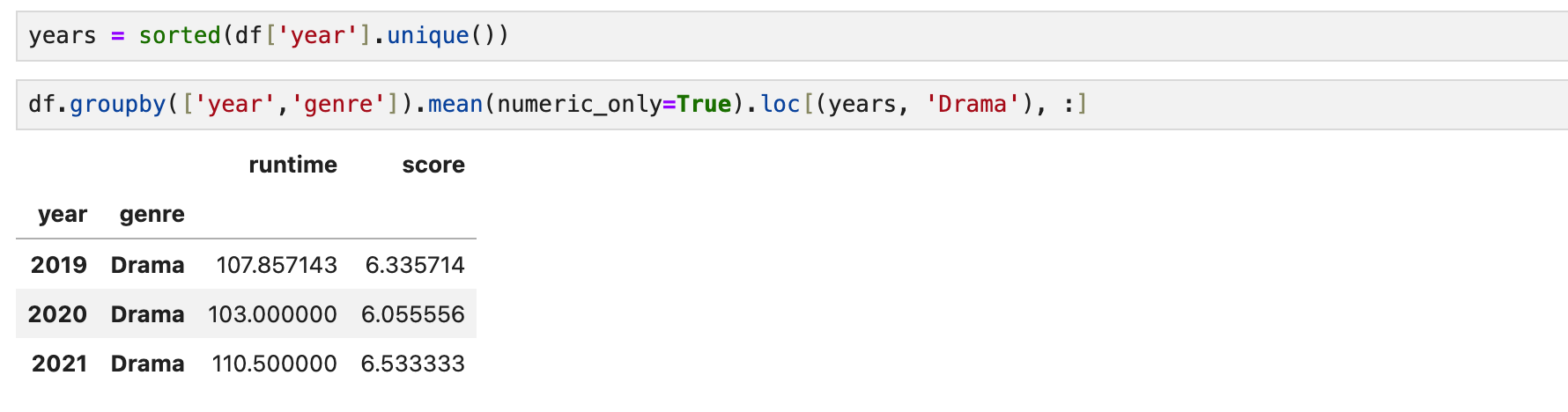
연도, 장르 순서로 그룹을 묶었을 때
연도에 접근하는 것은 가능하다. 그래서 2020년도 정보만 불러올 수 있다.

그러나 바로 장르에 접근하는 것은 불가능하다
연도를 거쳐서 장르에 접근해야 한다.

장르를 여러개 가져올 때는 리스트형태로 만들어주고
뒤에 콜론을 넣어줘야 한다.

연도도 여러개 가져올 때 리스트로 가져온다.

이때 연도 정보가 너무 많아지면 하나하나 쓰기 어려우니
sorted()
함수를 이용해 연도 정보만 변수에 저장해준다.
그리고 연도 위치에 years라는 변수를 넣어준다.
실습
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
# 여기에 코드를 작성하세요.
olympic_df.groupby(['sport','sex'])['height','weight'].mean()
다양한 통계값 계산하기
데이터를 가져온다.

원래는 원하는 통계값을 한 번에 확인했는데 여러개를 한 번에 볼 수 있는 방법이 있을까?
바로
agg()
agg() 함수 안에 원하는 통계를 작성해서 가져올 수 있다.

여러개의 경우 리스트형식으로 작성한다.

만약 컬럼별로 다른 통계값을 보고 싶다면 딕셔너리 형태로 넣어주면 된다.

실습
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
# 여기에 코드를 작성하세요.
olympic_df.groupby('sport')['age'].agg(['min','max'])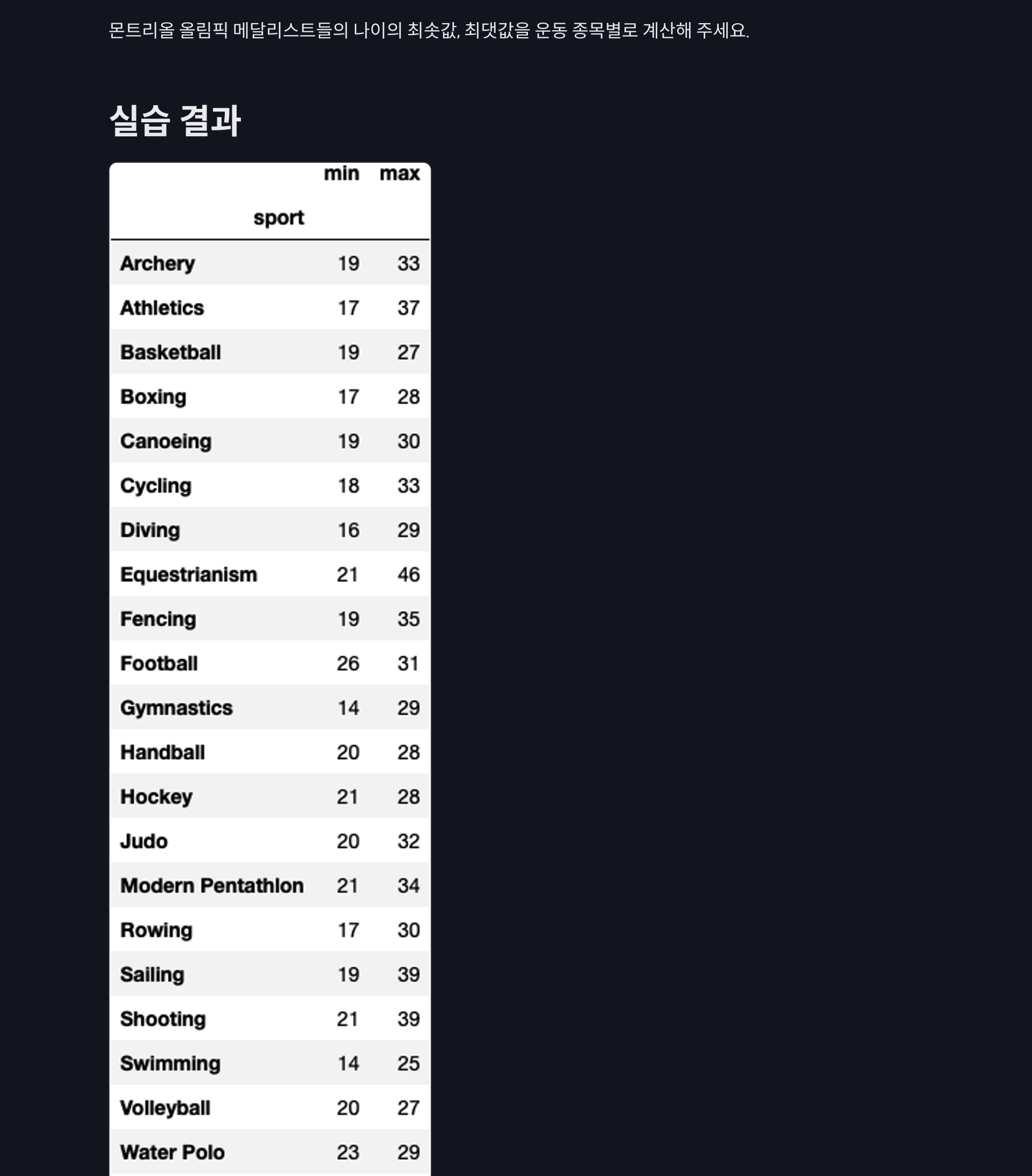
피벗테이블
기본 데이터 불러오기

그룹바이

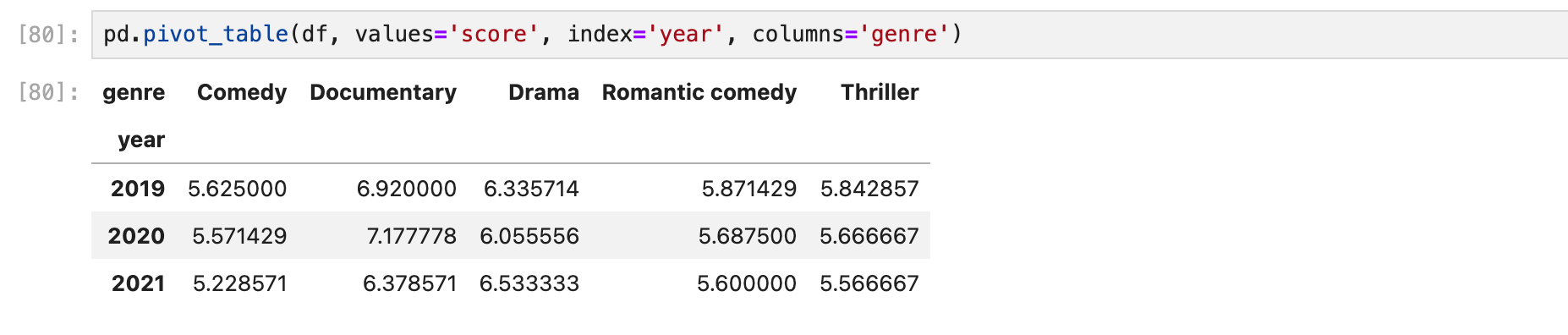
pivot_table()
피벗테이블을 이용하면 인덱스와 컬럼을 모두 불러오고 좀 더 깔끔한 표형태로 볼 수 있다.
aggfunc 파라미터로 통계값도 구할 수 있다.

각각 리스트로 여러 값을 가져올 수도 있다.
만약 컬럼이 너무 많은 경우에는 피벗을 사용하는 것보다 그룹바이를 쓰는 게 더 깔끔할 수 있다.
그리고 피벗보다 그룹바이의 계산속도가 더 빠르다.
상황에 따라 알맞은 걸 골라서 쓰면 된다.
실습
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
# 여기에 코드를 작성하세요.
pd.pivot_table(olympic_df, index='team', columns='medal', aggfunc='size').fillna(0).sort_values(
by=['1st', '2nd', '3rd', 'team'],
ascending=False
)
원하는 시간 간격으로 묶기
데이터 가져오기
미리 데이트타임으로 바꿔서 들고오고, 결측값은 없애줌
인덱스를 주문날짜로 바꿔줌
resample()
을 사용하여 일자별 합계를 구한다.

월별 합계를 구한다.
원래 M 인데 업뎃된건지 ME로 쓰라고 빨간박스가 나온다

연도 합계도 마찬가지
원래 Y인데 YE로 쓰라는 빨간 박스가 나왔다.

이렇게 날짜별로 묶어서 계산하기 편한 방법이다.
코드잇 19. 그룹별로 분석하기