
통계 기본 상식
평균 mean : 데이터 합계 / 데이터 개수
중간값 median : 데이터 정렬 -> 중간에 있는 값 / 데이터가 짝수라면 가운데 있는 중간값 2개를 더하고 2로 나눈 평균값
최솟값 minimum value
최댓값 maximum value
모든 수를 4등분했을 때
25% 위치 = 1사분위수 = Q1
50% 위치 = 2사분위수 = Q2 = 중간값
75% 위치 = 3사분위수 = Q4
describe()
4개 컬럼이지만 수치형 데이터에 대해 계산하는 함수라서 수치형 데이터 3가지만 나옴

4개 컬럼을 다 보고 싶다면 아래와 같이 작성한다.
그러면 범주형 데이터도 볼 수 있다.
df.describe(include='all')
top : 최빈값 : 가장 많은 값
freq : 프리퀀시 : 몇 번 등장하는지
평균 vs 중간값
평균
매장별 설문조사를 했을 때 평균값은 다르지만 중간값으로 하면 다 같다.
중간값
튀는 값이 섞여있을 때 사용
대부분 연봉이 3000~6000인데 10억인 사람이 들어가있는 경우 중간값을 사용해야 한다.
사분위수 계산하기

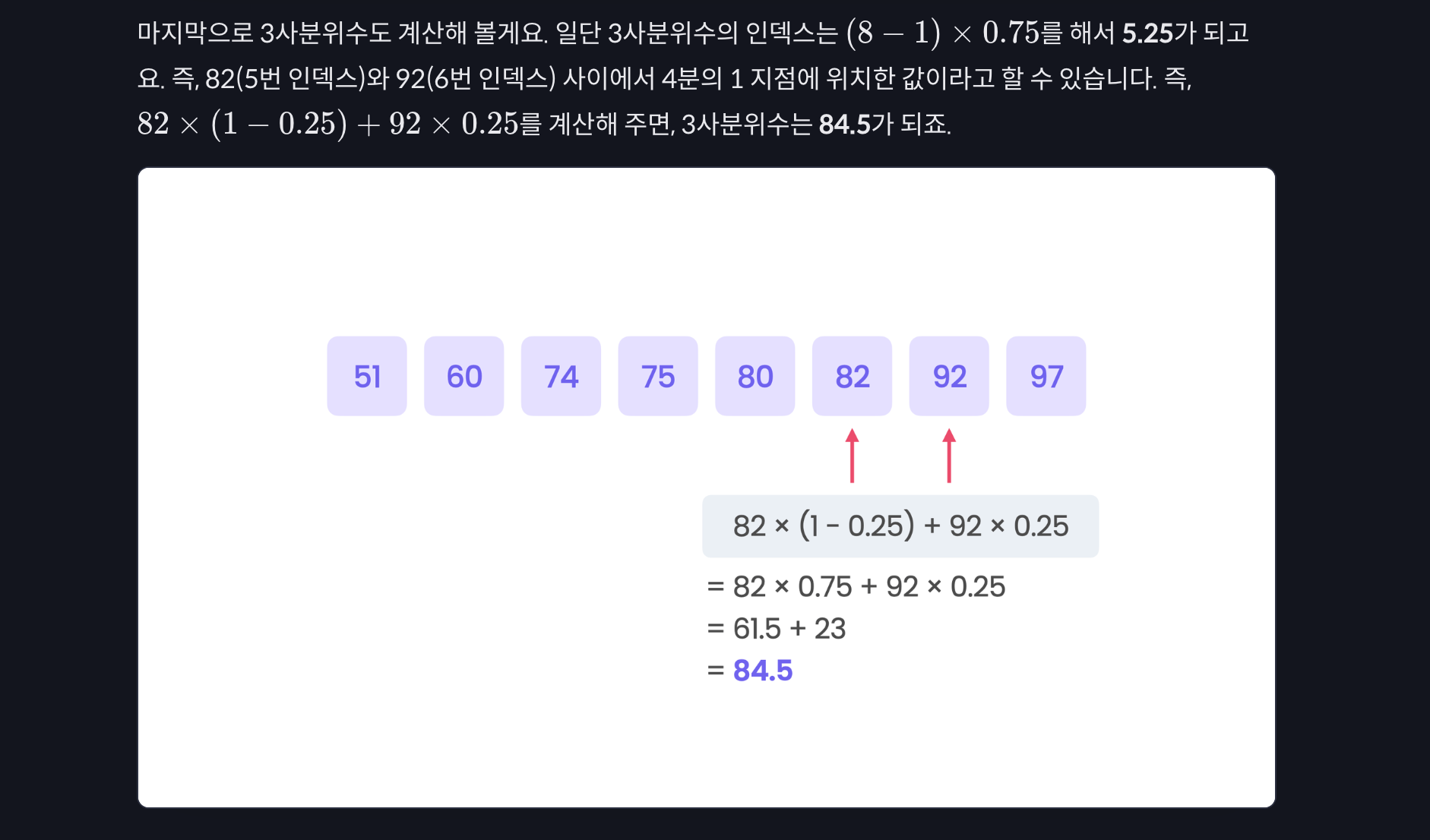
박스 플롯과 이상점
IQR : 정상범위의 기준
하늘색 상자 : 정상범위
이상점 : 너무 튀는 데이터, 위/아래 점들
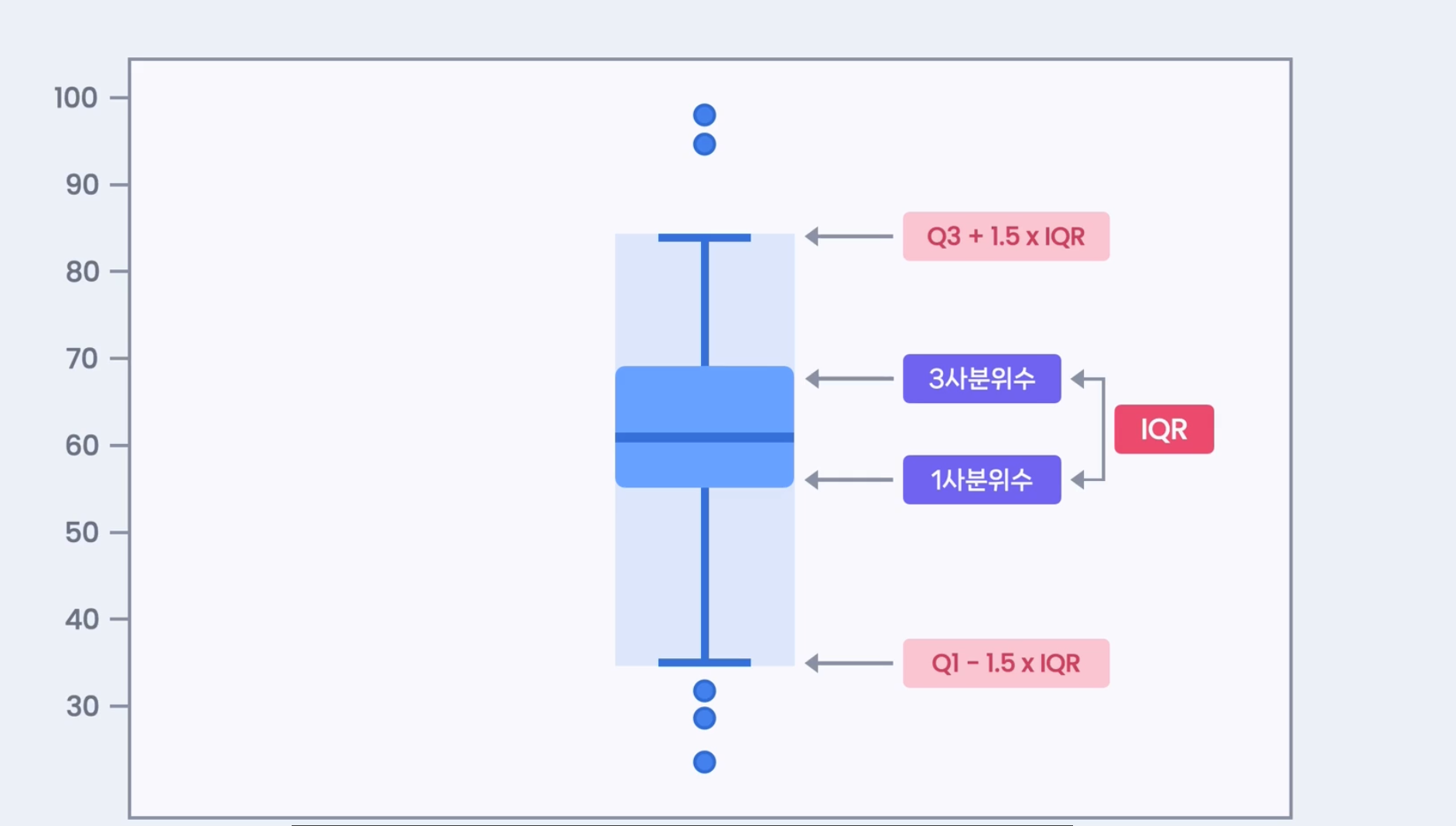

IQR 계산

해석
과학은 대부분의 학생이 잘 봄
수학은 점수가 다양함
영어와 과학은 이상점도 많음

히스토그램
수치형 데이터
- 이산형 데이터
- 연속형 데이터 (키, 몸무게)
히스토그램
주로 연속형 데이터를 범위를 정해서 구분할 때 사용
이산형 데이터도 구간을 정해놓고 히스토그램을 만들 수 있음

kind = 'hist'

bins = 막대의 개수 지정

실습
import pandas as pd
car_df = pd.read_csv('data/car.csv')
# 여기에 코드를 작성하세요.
car_df
hyundai_price = car_df.loc[car_df['manufacturer'] == 'HYUNDAI']
hyundai_price
hyundai_price['price'].plot(kind='hist', bins=10)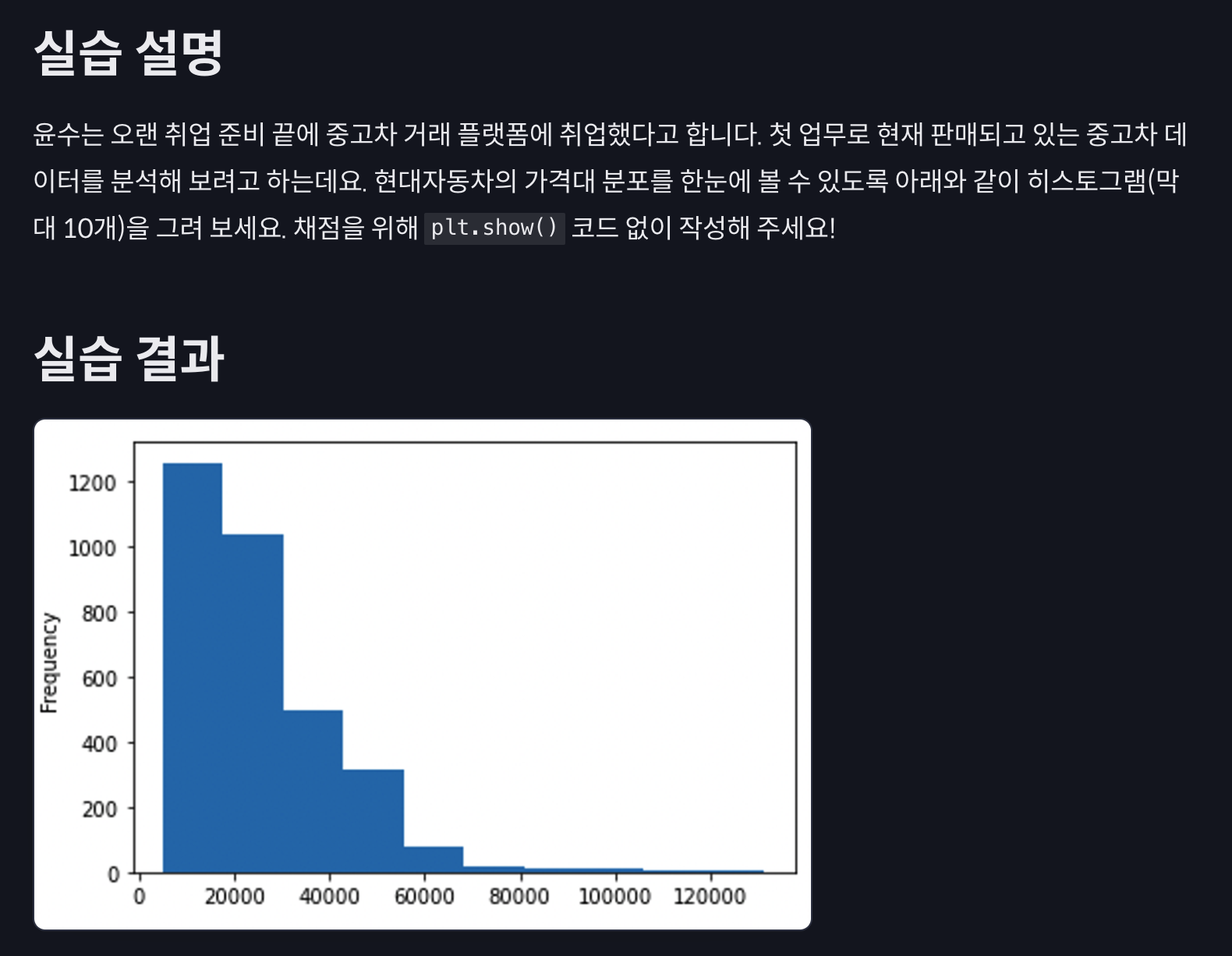
모집단과 표본
기술 통계
데이터 요약 및 핵심적인 특징 파악
추론통계
일부 데이터인 표본을 기반으로 추론을 하는 것
확률 밀도 함수와 KDE plot
확률 밀도 함수
연속형 데이터를 좀 더 세밀하게 표현하기 위해 필요한 것
KDE plot
전체 데이터 분포 즉 PDF에 대한 추정을 해서 하나의 부드러운 곡선 모양을 그릴 수 있음


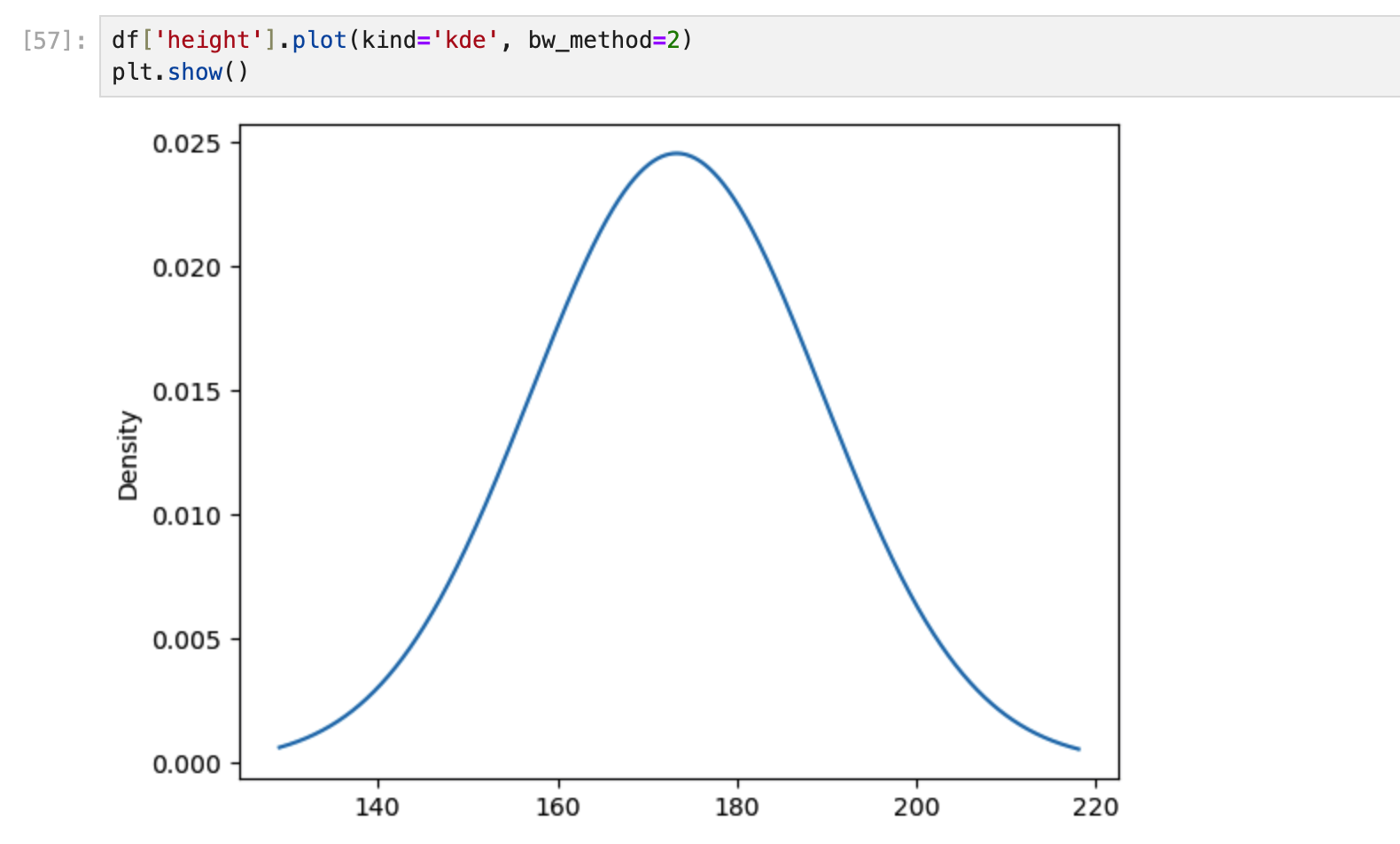
데이터 분포의 모양
정규 분포
가운데만 볼록하게 솟아있고 양 끝으로 갈수록 낮아지는 형태 (좌우 대칭)
중간에 데이터가 몰려 있고, 엄청 크거나 엄청 작은 값들은 상대적으로 적음
분산과 표준편차
분산
1. 데이터의 평균 구하기
2. 편차 구하기 : 각 값에서 평균을 빼준다
3.각 편차 값을 제곱(양수로 통일시키고 편차가 큰 값을 부각시키기 위해)
4.제곱한 값을 더 하고 그 값으로 평균을 구한다.
표준 편차
분산값에 루트를 씌워준다.

표본으로 구할 때는?
평균 구할 때 데이터 개수가 아닌, 데이터 개수-1 로 나누어준다.
var : 분산
std : 표준편차

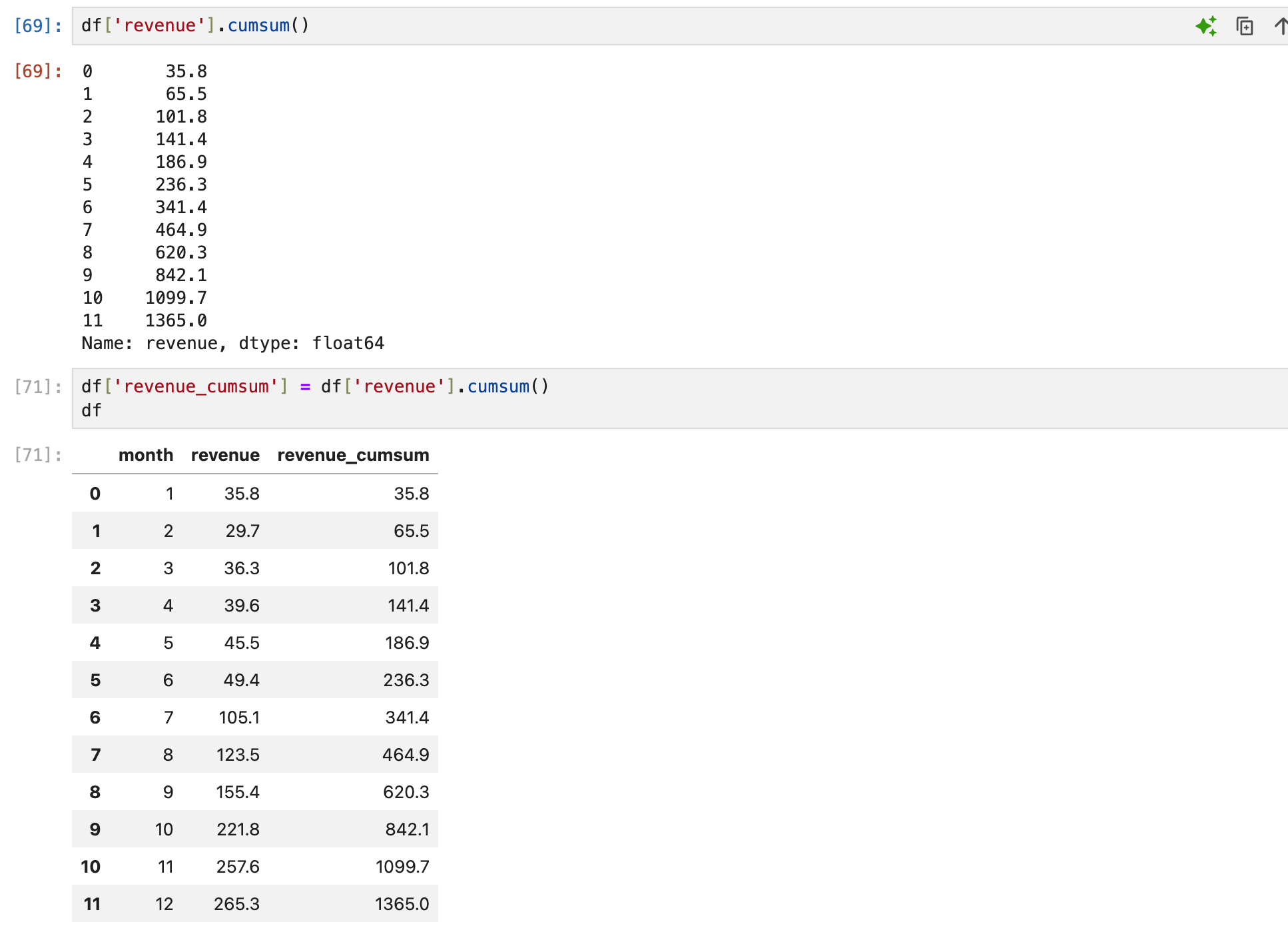
누적값 계산하기
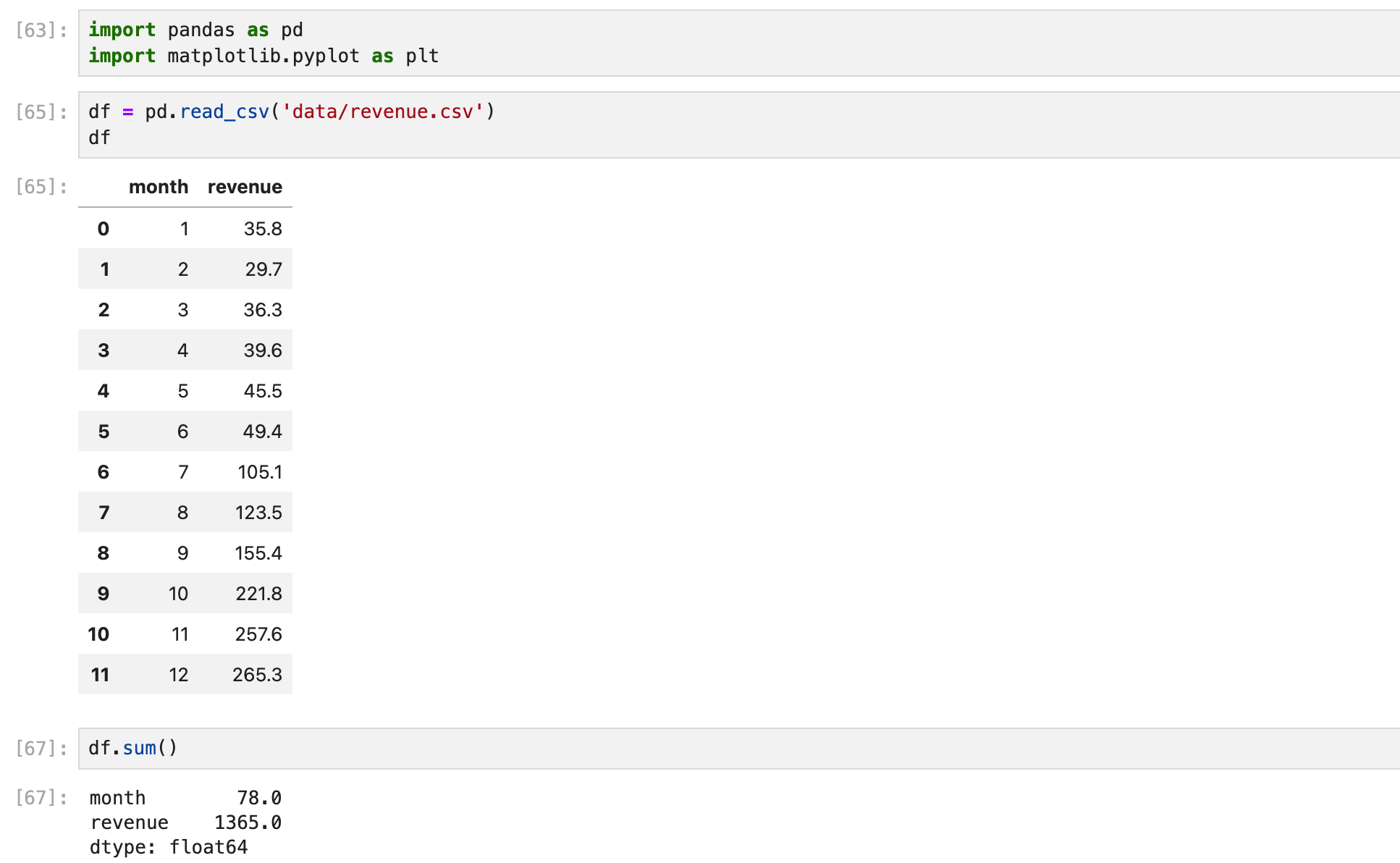
누적합계 함수

누적곱 함수

실습
import pandas as pd
user_df = pd.read_csv('data/user.csv')
# 여기에 코드를 작성하세요.
user_df['user_day'] = user_df['register'] - user_df['unregister']
user_df['net_user_cumsum'] = user_df['user_day'].cumsum()
user_df.plot(x='day', y='net_user_cumsum', kind='bar')
코드잇 11. 통계 기본 상식과 그래프
'마케팅 > 데이터 분석' 카테고리의 다른 글
| [파이썬] DataFrame 기본기 (0) | 2025.03.13 |
|---|---|
| [파이썬] seaborn (0) | 2025.03.13 |
| [파이썬] pandas (0) | 2025.02.25 |
| [파이썬] Matplotlib (1) | 2025.02.25 |
| [파이썬] NumPy (0) | 2025.02.25 |



