
DataFrame 살펴보기
info()
데이터 프레임의 정보 확인하기
describe()
데이터 통계량 확인하기

include='all' (파라미터)
모든 컬럼에 대한 요약

sort_values(by='칼럼명')
특정 칼럼을 기준으로 정렬 (기본이 오름차순)

내림차순

기타
괄호가 붙어있는 것은 함수, 괄호가 없는 것은 변수라고 보면 된다.
head() # 데이터프레임의 앞에서 5행
tail() # 데이터프레임의 뒤에서 5행
info() # 데이터프레임 정보
sort_values()
describe()
dtypes # 데이터 프레임 타입
shape # 데이터프레임 크기엑셀 파일 불러오기
항상 csv만 불러왔는데 excel을 불러오고 싶다면 아래와 같이 작성하면 된다.
loan_df = pd.read_excel('data/loan.xlsx')그렇지만 엑셀은 몇 가지 파라미터를 설정해주어야 한다.

여러개의 시트로 이루어져 있을 때, 어떤 시트에서 불러올지 정해준다.
loan_df = pd.read_excel('data/loan.xlsx', sheet_name=1)
#인덱스는 0부터 시작 1은 두 번째 시트를 의미함
A1셀부터 시작되지 않는 경우 시작 행과 열을 설정해준다.
loan_df = pd.read_excel('data/loan.xlsx', sheet_name=1, header=3, usecols='B:H')
#header 0,1,2,3 : 4번째 줄에 컬럼명이 있으니 3으로 작성
#usecols : B열부터 H열까지 데이터가 있으니까 B:H로 작성
인덱스, 컬럼명, 데이터 타입 설정하기
인덱스 변경하기
그냥 숫자 0~ 인덱스 말고, 의미있는 컬럼을 인덱스로 지정할 수 있다.
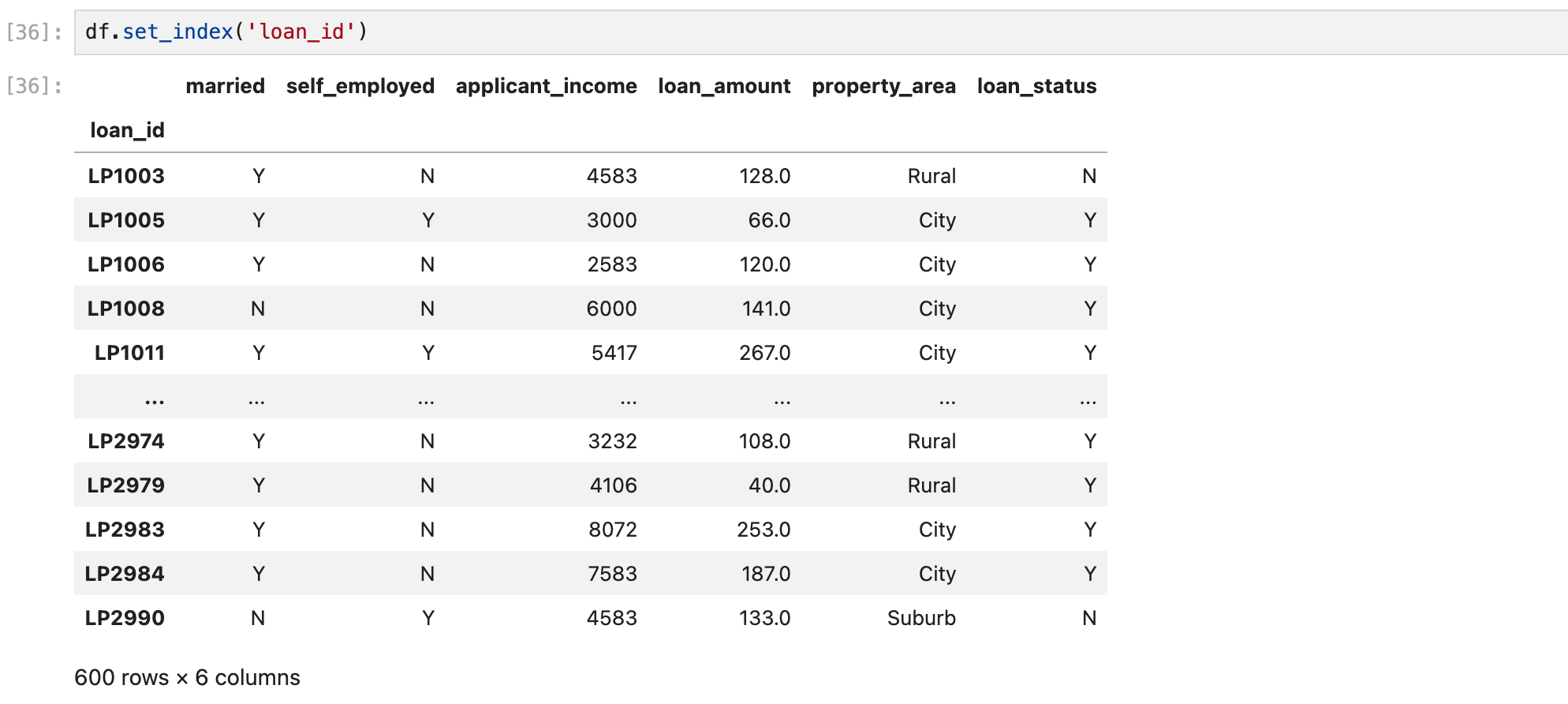
이때 그냥 쓰면 리턴하고 끝이니까 다시 정의를 해주어야 됨

인덱스 리셋하기

columns 만 보기

columns 이름 바꿔주기

딕셔너리를 만들어서 특정 컬럼만 이름 바꿔주기

데이터 타입 바꿔주기
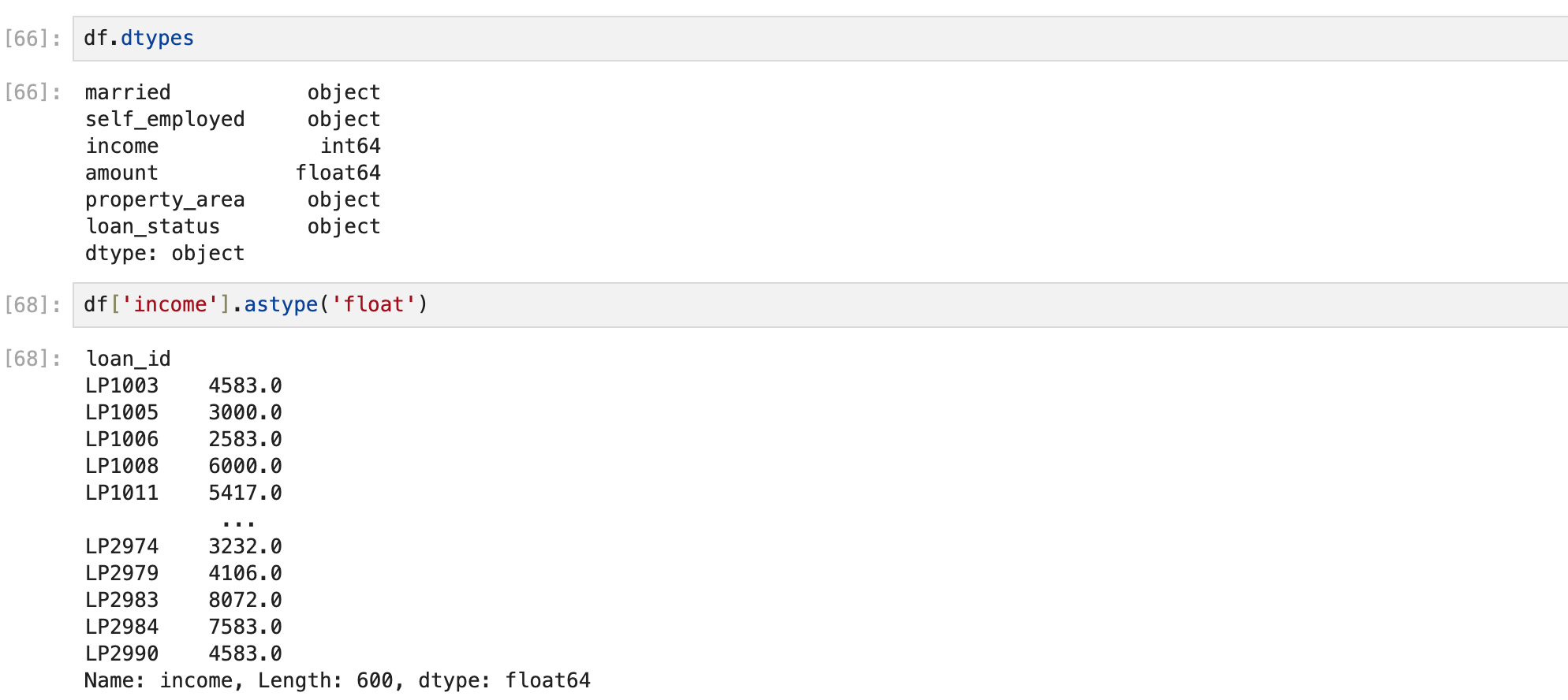
이것도 타입 바꾼 걸 다시 저장해주어야 한다.

Series 살펴보기
특정 칼럼을 불러오면 시리즈로 결과가 출력된다.

시리즈도 타입을 확인할 수 있고, 통계 요약 정보도 확인할 수 있다.

오브젝트 타입의 컬럼도 똑같이 사용 가능하다.

특정 컬럼의 데이터 종류 가져오기

데이터가 몇 개 있는지 확인하기 (그러나 nan값은 안 나옴)

NaN값까지 나오게 하는 법

차지하는 비율을 확인하는 방법

데이터 프레임과 시리즈 차이
df[['amount']]
df['amount']
실습 1
import pandas as pd
loan_df = pd.read_csv('data/loan.csv')
loan_df = loan_df.set_index('loan_id')
new_columns = {'married_or_not': 'married',
'self_employed_or_not': 'self_employed',
'applicant_income': 'income',
'loan_amount': 'amount'}
loan_df = loan_df.rename(columns=new_columns)
# 여기에 코드를 작성하세요.
loan_df['property_area'].value_counts(dropna=False, normalize=True)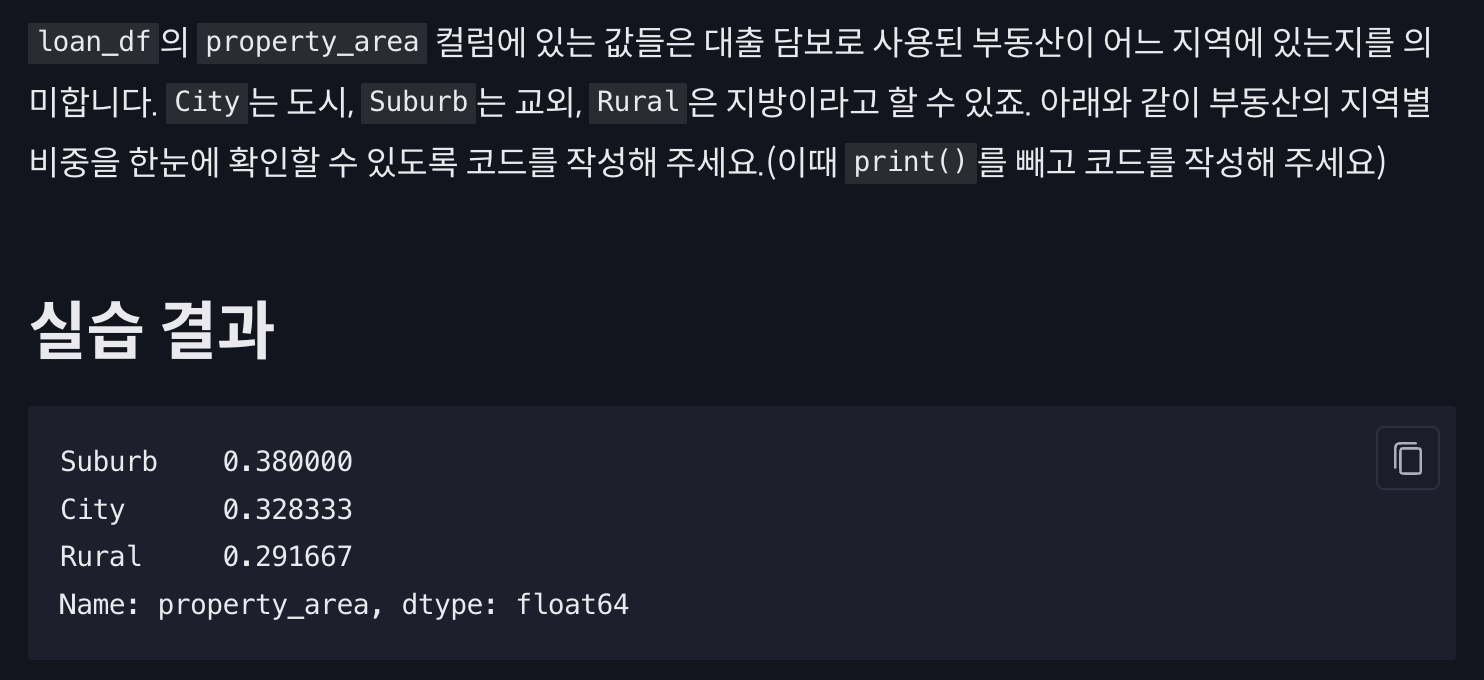
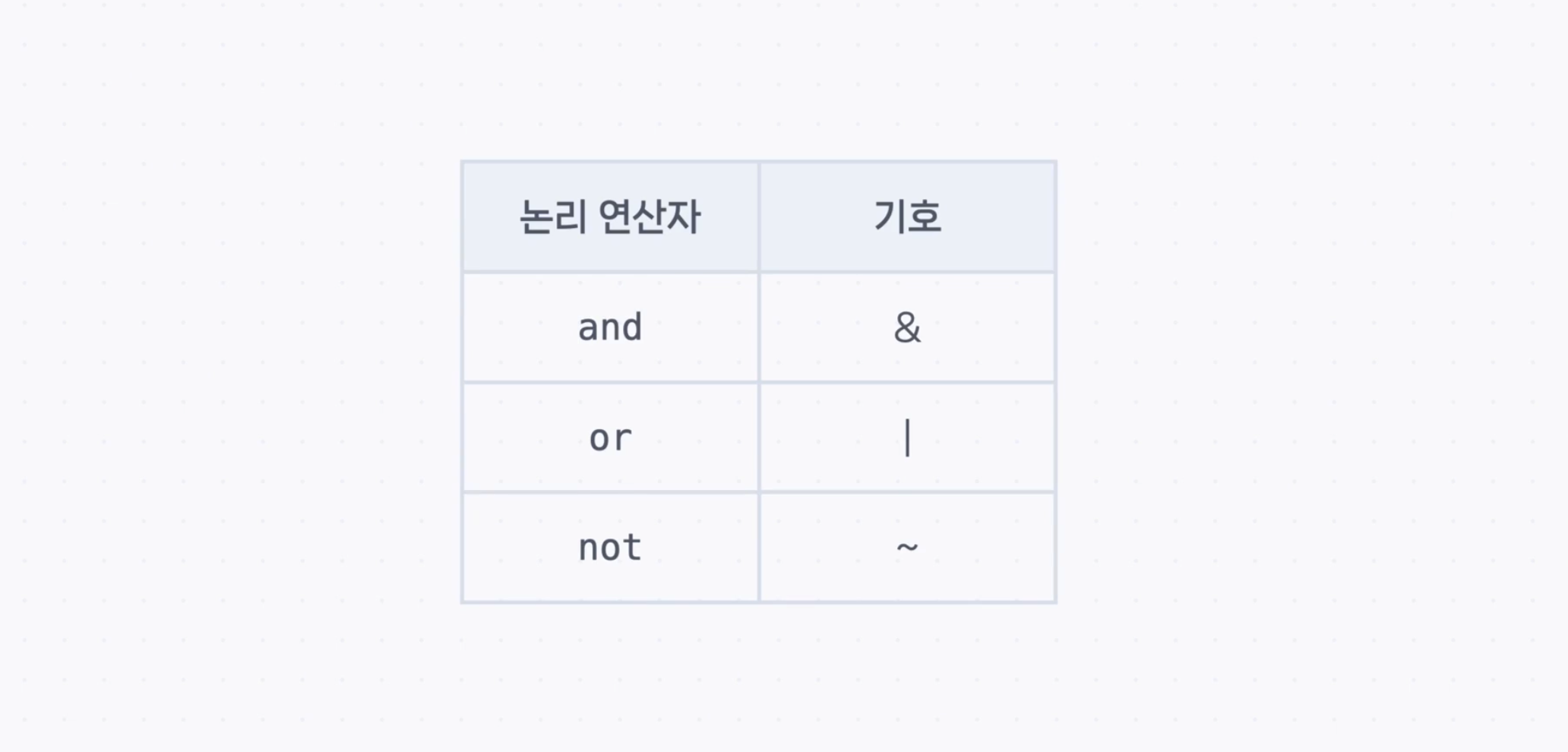
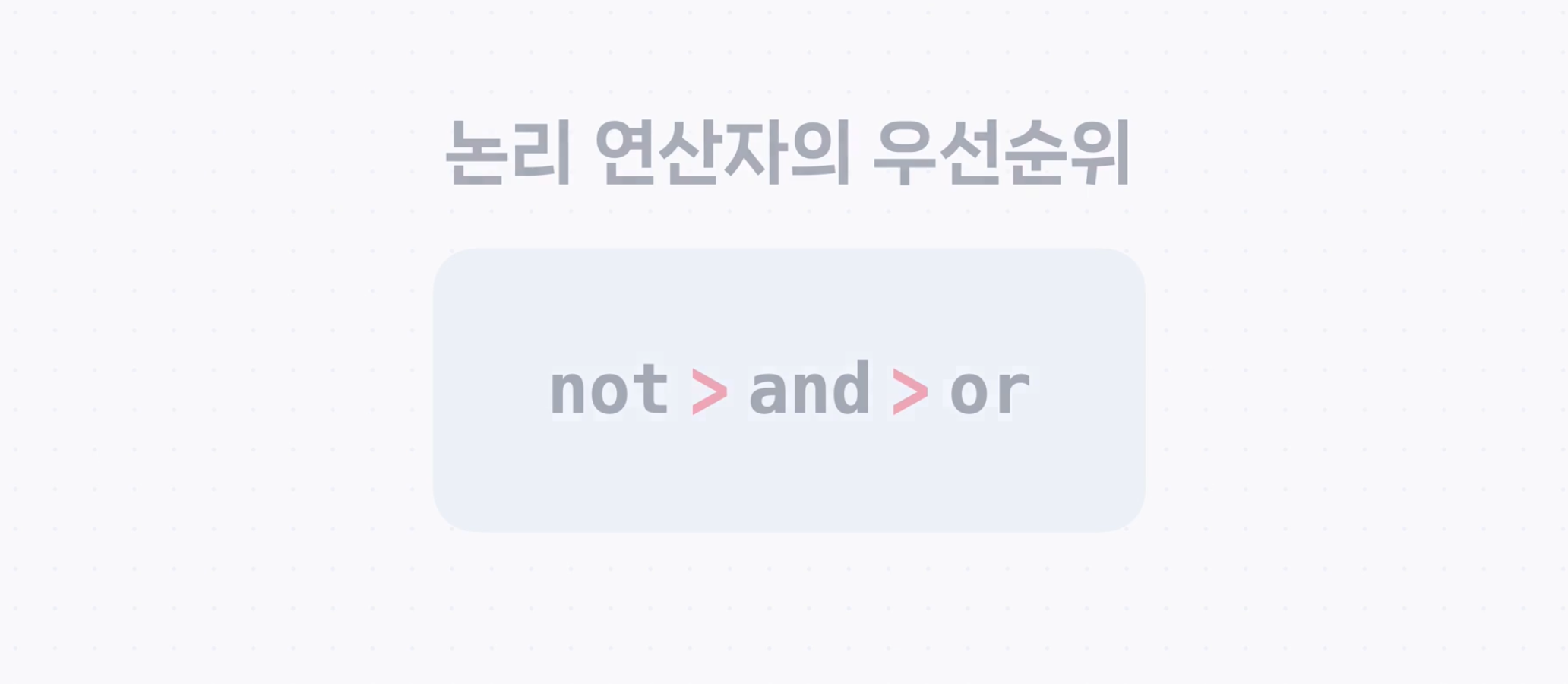
여러 개의 조건으로 불린 인덱싱하기



기본 데이터프레임

각 조건을 변수에 저장하고 원하는 조건대로 인덱싱하기


이렇게 짧은 조건은 변수에 저장하지 않고 한 번에 써도 됨


실습 1
import pandas as pd
loan_df = pd.read_csv('data/loan.csv')
loan_df = loan_df.set_index('loan_id')
new_columns = {'married_or_not': 'married',
'self_employed_or_not': 'self_employed',
'applicant_income': 'income',
'loan_amount': 'amount'}
loan_df = loan_df.rename(columns=new_columns)
# 여기에 코드를 작성하세요.
condition1 = loan_df['loan_status'] == 'Y'
condition2 = loan_df['self_employed'] == 'N'
condition3 = loan_df['income'] >= loan_df['income'].median()
group1 = loan_df[condition1 & condition2 & condition3]
group1
데이터 삭제하기
drop()

drop은 row를 삭제하는 함수라서 columns 삭제할 땐 지정을 해줘야한다.

axis
row 방향은 0
column 방향은 1

실습 1
import pandas as pd
loan_df = pd.read_csv('data/loan.csv')
loan_df = loan_df.set_index('loan_id')
new_columns = {'married_or_not': 'married',
'self_employed_or_not': 'self_employed',
'applicant_income': 'income',
'loan_amount': 'amount'}
loan_df = loan_df.rename(columns=new_columns)
# 여기에 코드를 작성하세요.
loan_df = loan_df.drop('loan_status', axis = 1)
loan_df
가공한 데이터 내보내기
csv
to_csv()는 인덱스에 있는 값들을 컬럼으로 만들어버린다.
내가 컬럼을 loan_id로 변경한 뒤 저장했는데도, 다시 읽어들이면 맨 앞에 숫자 인덱스가 붙는 걸 볼 수 있다.
이때 index를 False로 바꾸면된다.

Excel
to_excel()

코드잇 13. DataFrame 기본기
'마케팅 > 데이터 분석' 카테고리의 다른 글
| [파이썬] 문자 데이터 가공하기 (0) | 2025.03.13 |
|---|---|
| [파이썬] 데이터 다듬기 (0) | 2025.03.13 |
| [파이썬] seaborn (0) | 2025.03.13 |
| [파이썬] 통계 기본 상식과 그래프 (1) | 2025.03.09 |
| [파이썬] pandas (0) | 2025.02.25 |



