
데이터가 제대로 되어 있지 않으면 이상한 결과가 나온다.
원본 데이터를 다듬는 것이 중요하다.
결측값 찾기
기본 데이터 불러오기

info()
결측값 찾는 법 1
713개의 row 중에 rating(별점)만 700개라는 걸 알 수 있다.

isna()
결측값이 있으면 True, 없으면 False 로 데이터 프레임으로 보여준다.

isna().sum()
그냥 데이터프레임으로 보면 불편하다.
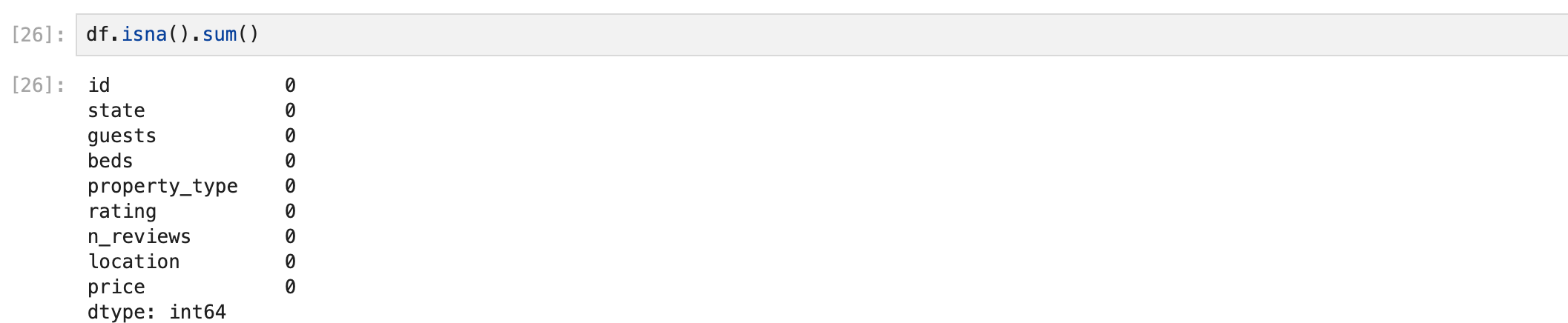
sum()함수를 사용하면 데이터프레임에서 true 값(1)을 더해준다. rating에 13개의 결측값이 있다는 것을 알 수 있다.

isna().any(axis=1)
모든 row를 검사하는 함수
0행부터 712행까지 결측값이 있는 행은 True로 보여준다.
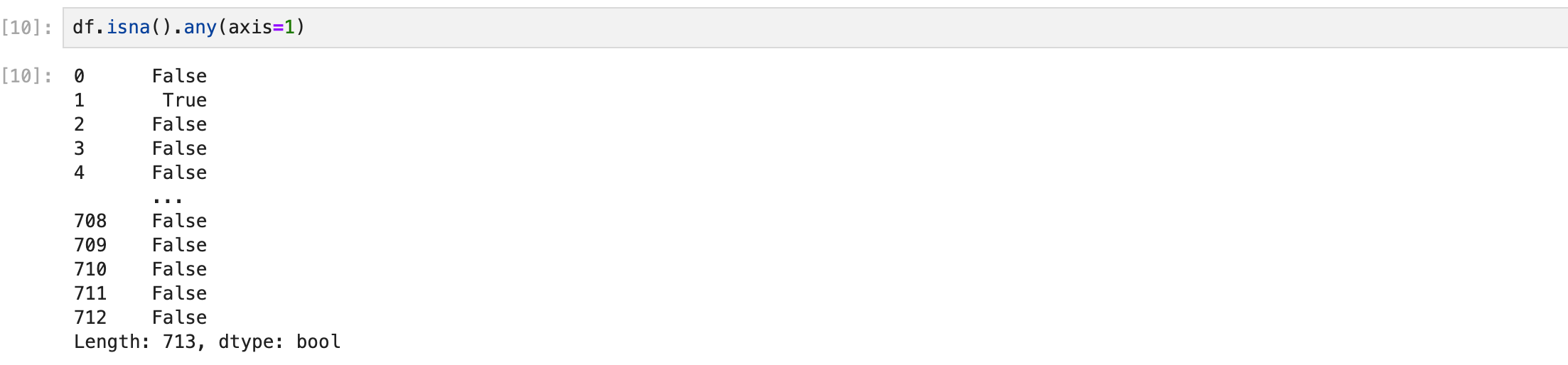
위에서 찾은 값만 데이터프레임으로 가져오면 결측값이 있는 row만 출력된다.
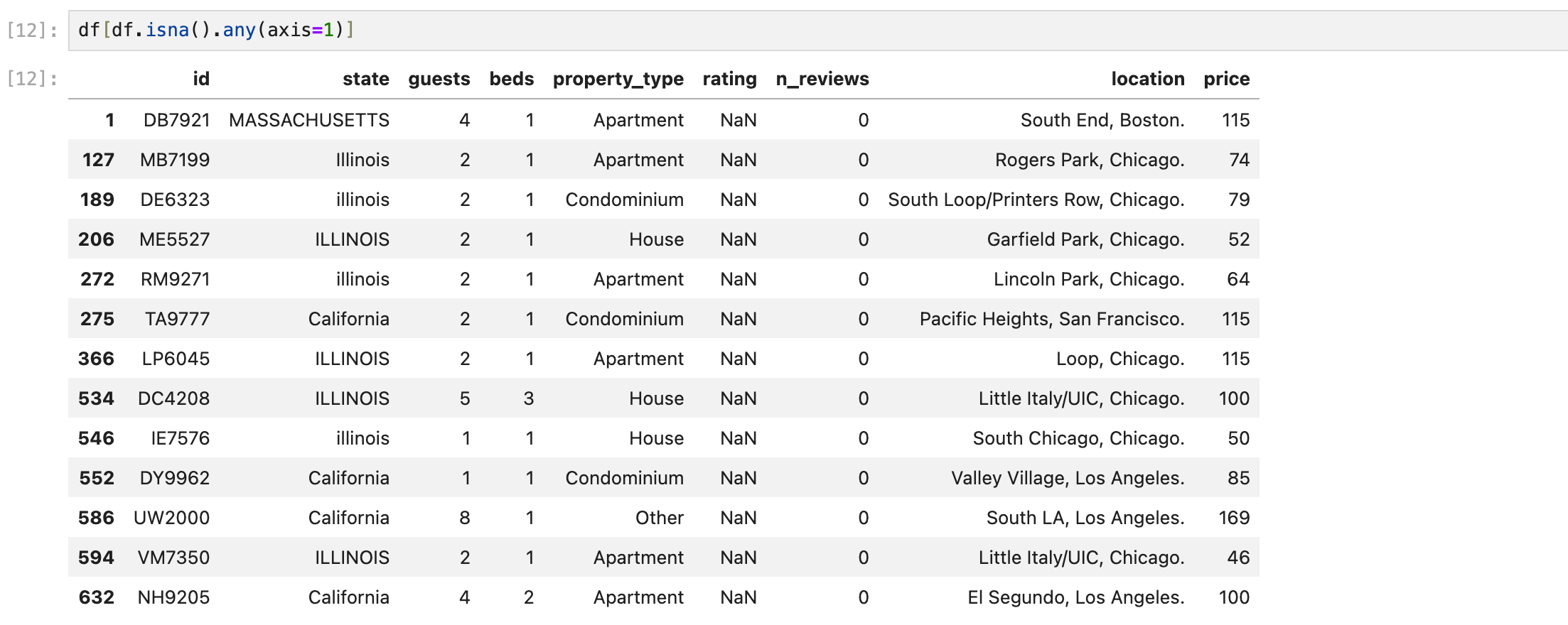
데이터를 보면 등록된 리뷰가 없어서 별점이 NaN로 나온 것을 알 수 있다.
결측값 처리하기

사용할 수 있는 데이터가 줄어든다는 단점이 있음

정확한 데이터는 아니지만 데이터가 줄어들지 않는다는 장점이 있음
결측값 삭제하기
dropna()
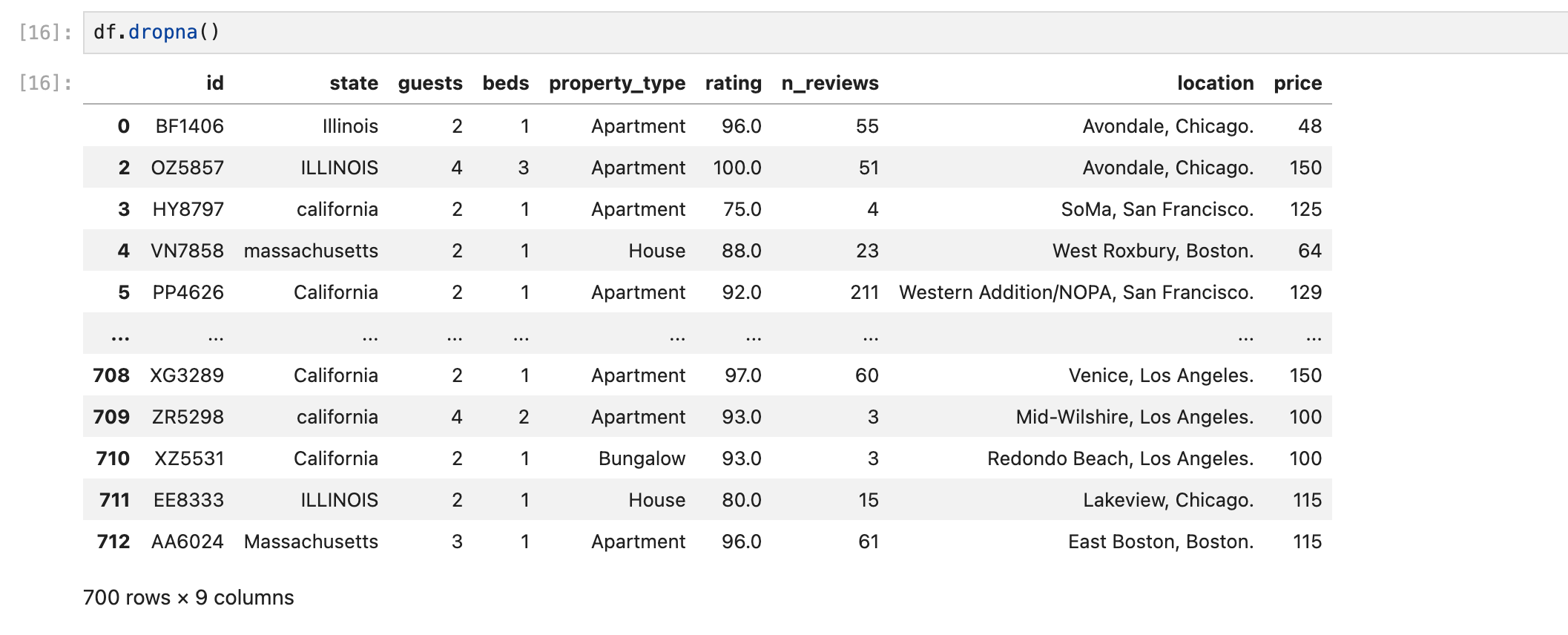
결측값 다른 값으로 채우기
먼저 해당 컬럼의 평균값을 구해준 뒤 변수에 저장한다.

그리고 아래 함수로 결측값을 채워준다.
fillna(변수명)
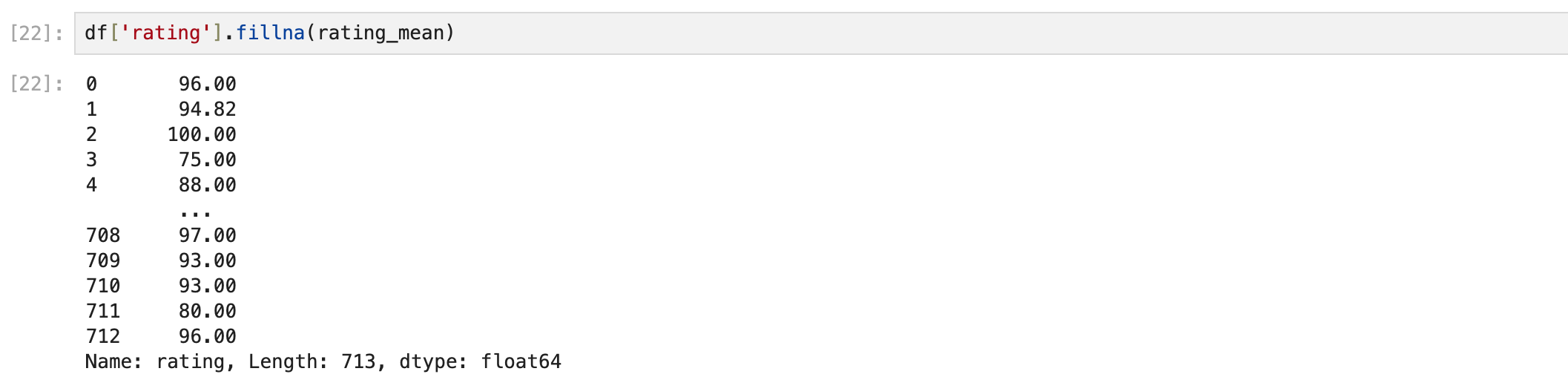
그러면 시리즈가 나오는데 이를 해당 컬럼에 저장하고 데이터프레임을 확인하면 잘 채워진 것을 볼 수 있다.
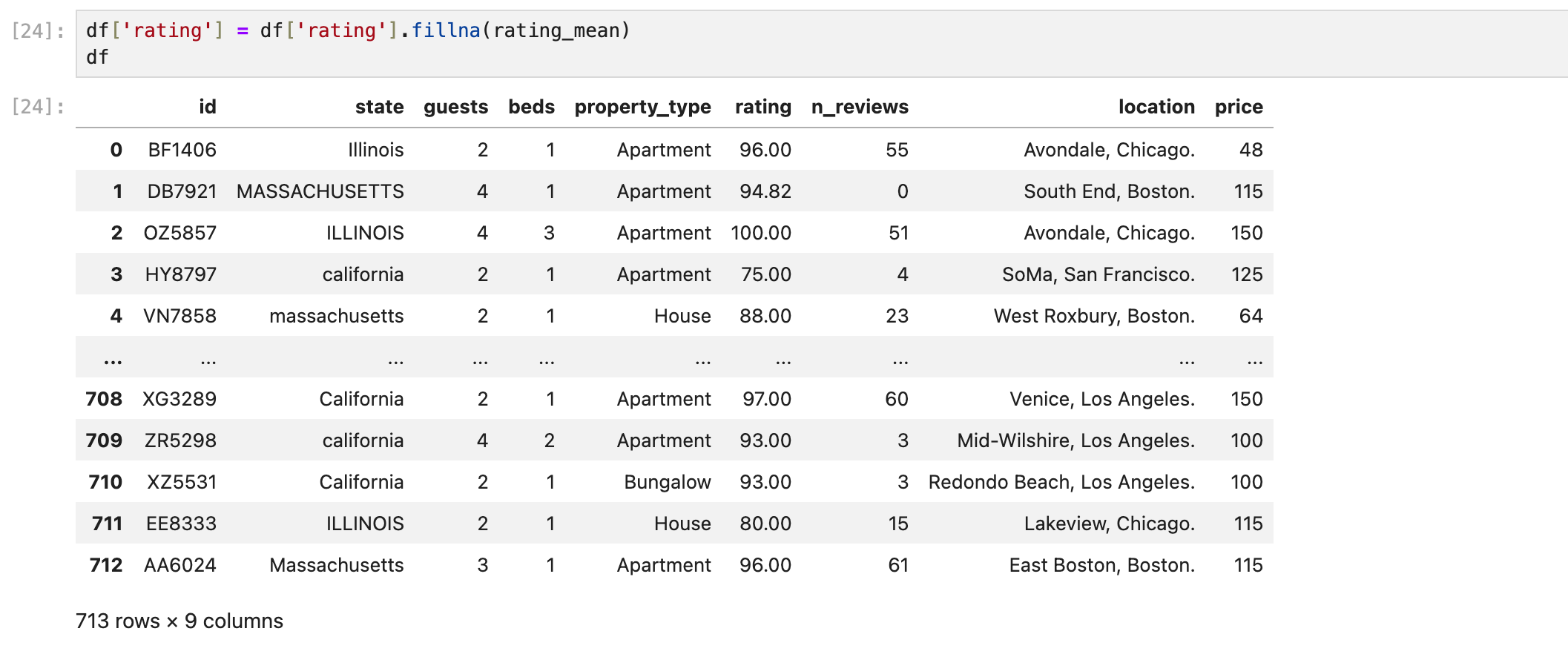
확실히 확인하기 위해 isna().sum()으로 결측값의 수를 확인한다.
실습 1
import pandas as pd
cellphone_df = pd.read_csv('data/cellphone.csv')
# 여기에 코드를 작성하세요.
mini13_weight = 140
cellphone_df['weight'] = cellphone_df['weight'].fillna(mini13_weight)
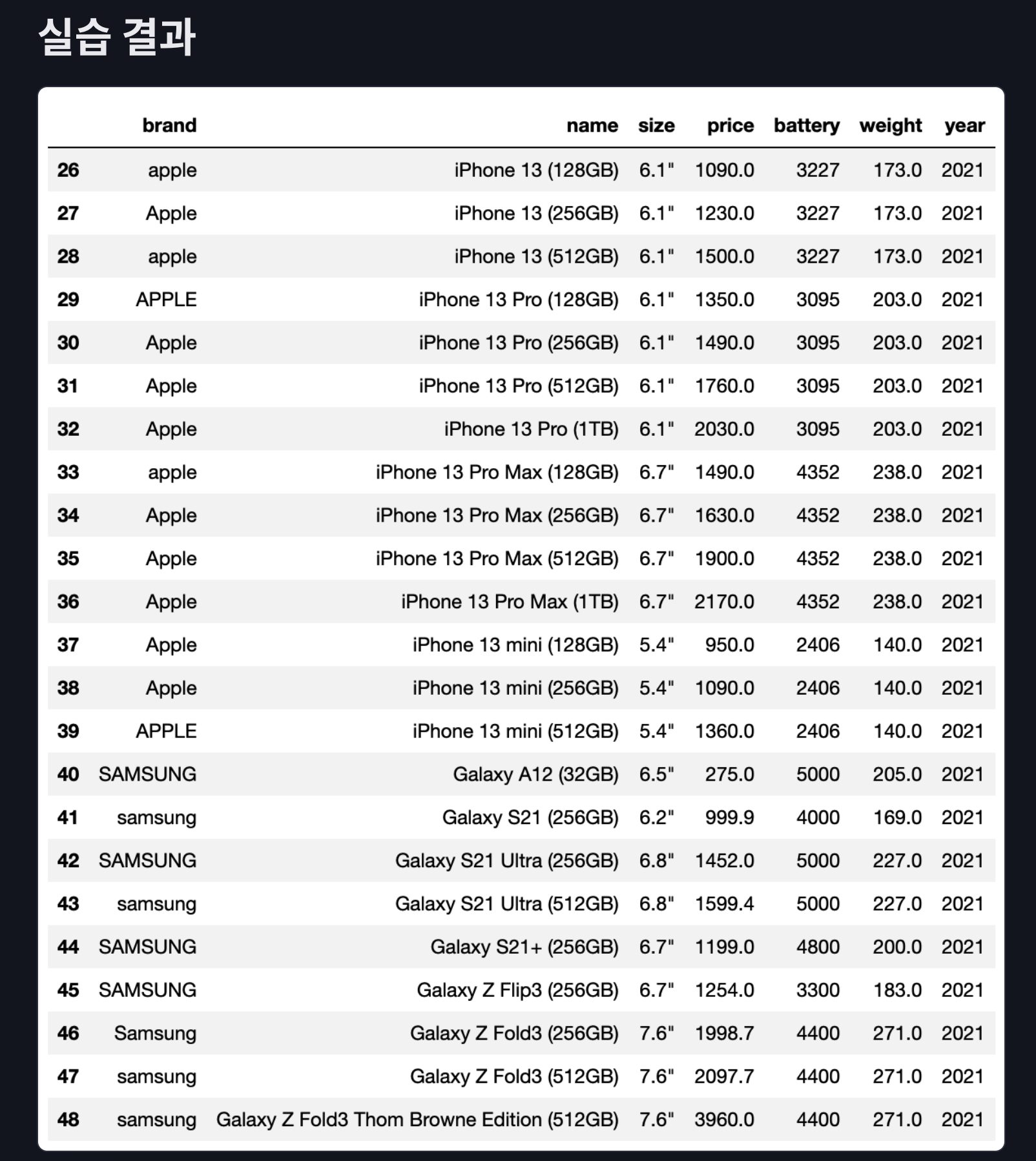
cellphone_df[cellphone_df['year'] == 2021]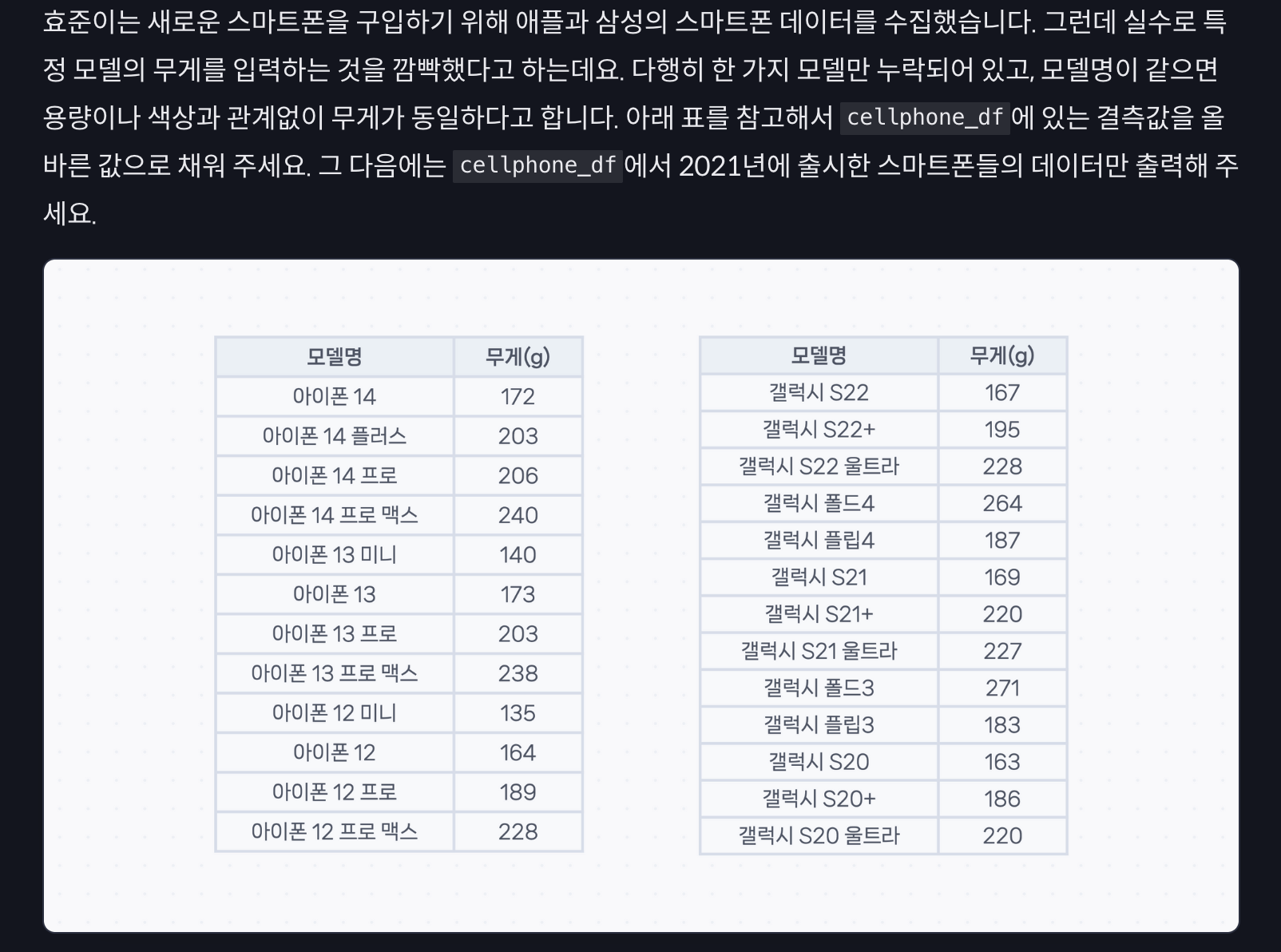
중복값 찾기
기본 데이터
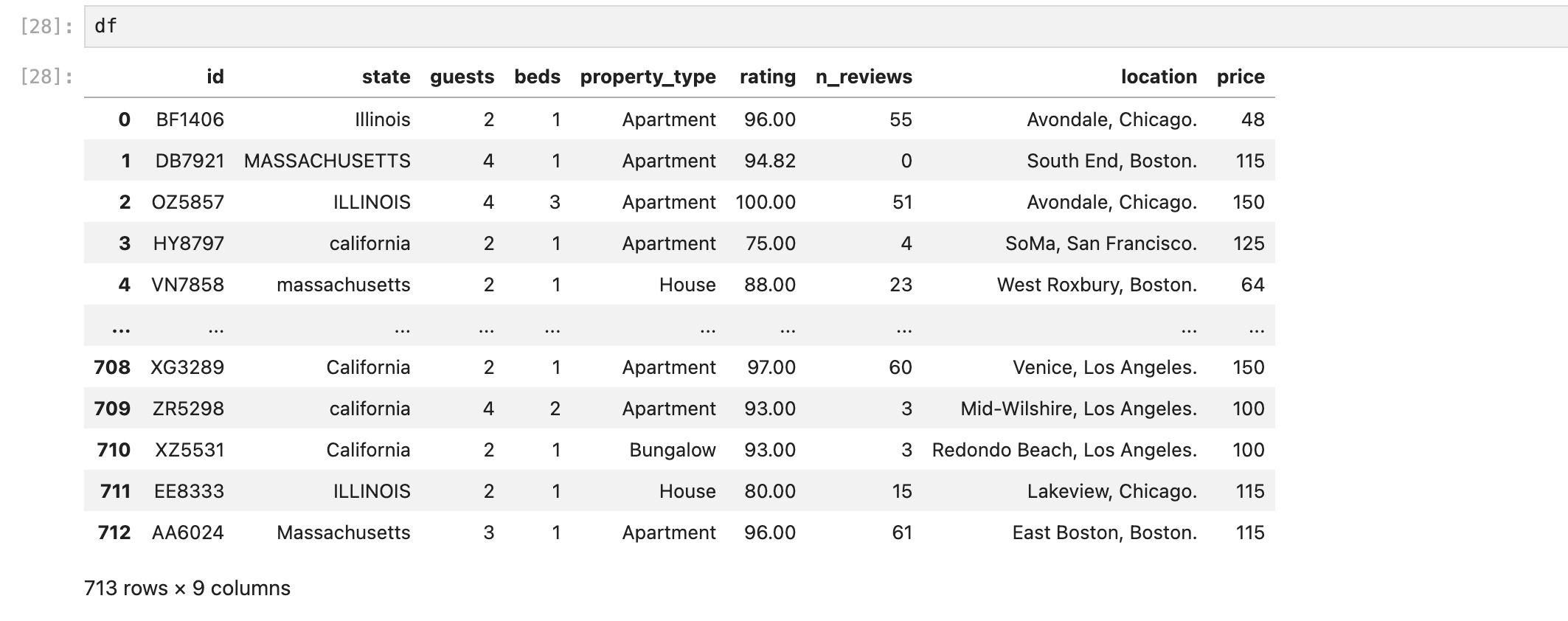
duplicated()
중복값이 있으면 True로 나오는 함수.
그리고 아까처럼 sum()을 사용하여 True 개수를 더해줘서 총 중복값이 2개라는 것을 확인할 수 있다.
데이터프레임으로 보면 전체 컬럼의 데이터가 중복되는 걸 볼 수 있다.

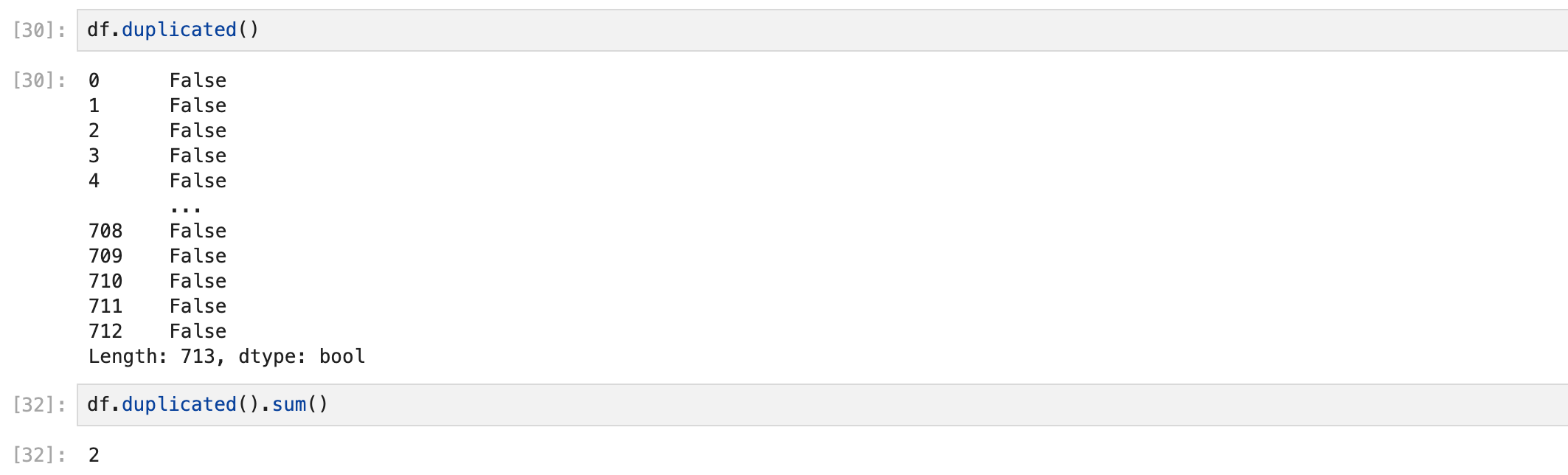
subset='컬럼명'
파라미터를 넣으면 컬럼명이 id인 컬럼만 중복된 결과를 보여준다.
여기서 마지막 2개의 행을 보면 아이디값이 다르다는 걸 볼 수 있다.
그 이유는 중복값을 찾아올 때 처음 나온 값은 중복으로 안치고, 2번째 값부터 중복값으로 생각하기 때문이다.
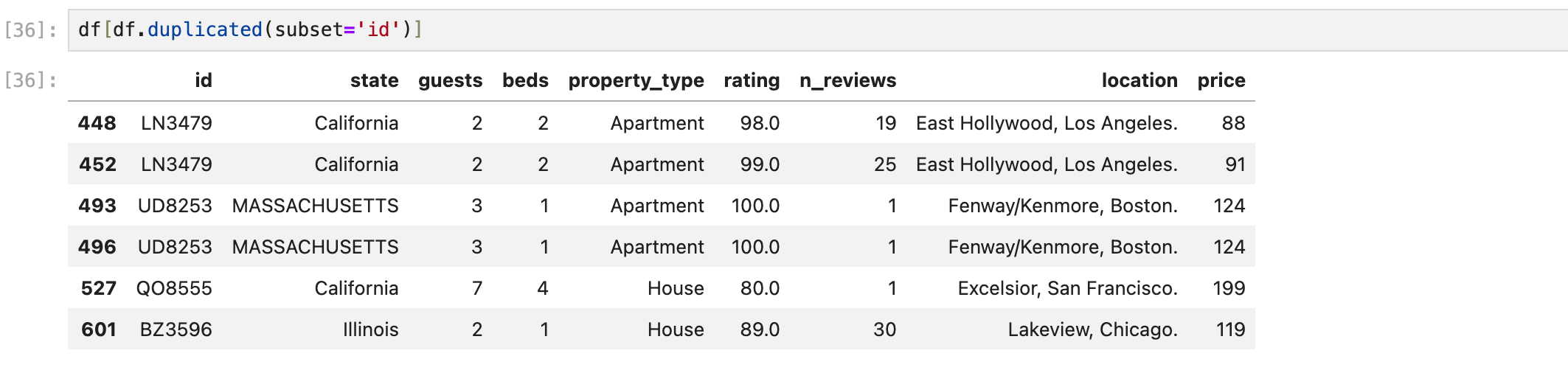
keep = 'first'
keep이라는 파라미터의 기본값이 first이다.
즉 위 데이터프레임과 같은 결과를 보여준다.
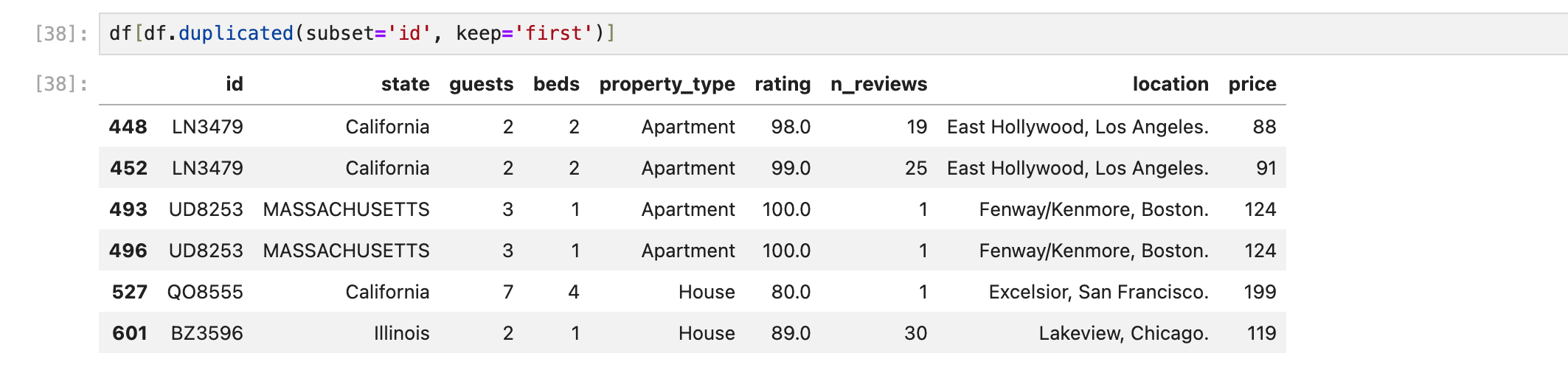
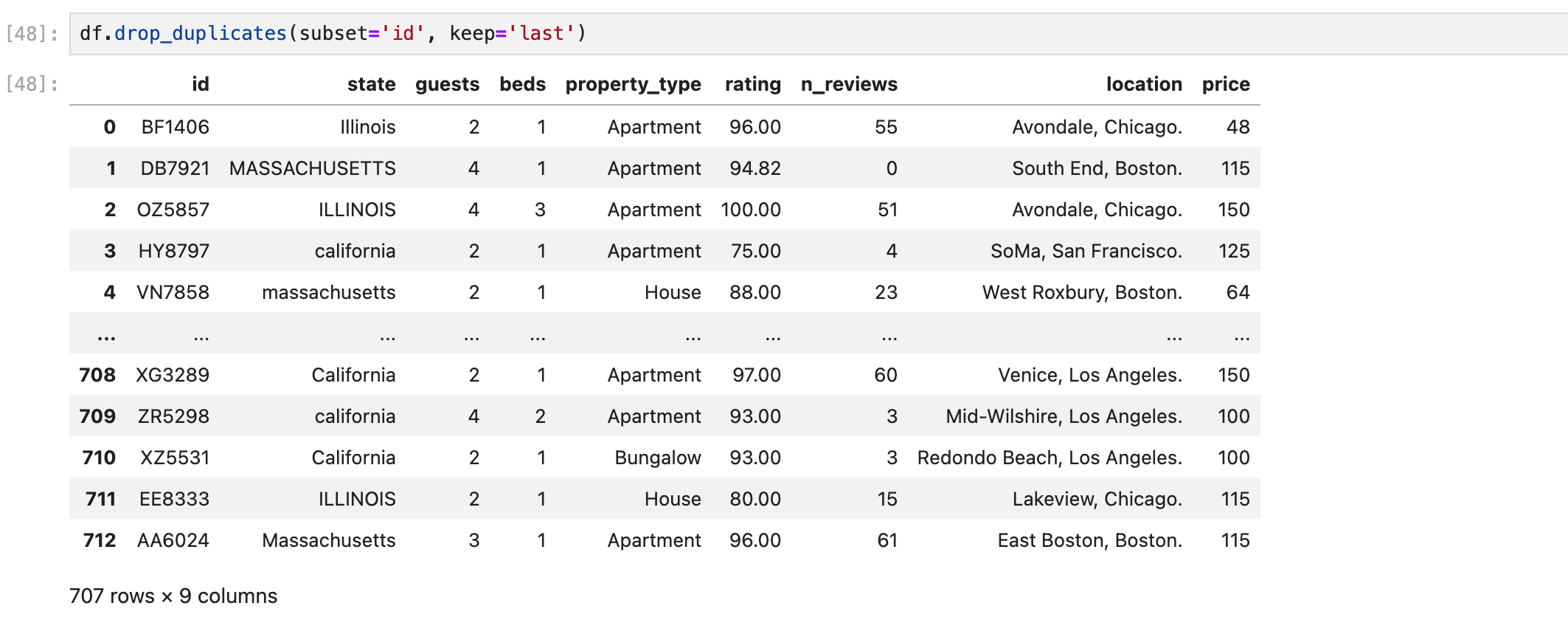
keep = 'last'
여기서 keep의 값으로 last를 쓰면, 맨 뒤에 있는 값은 빼고 나머지 값을 중복값으로 데려온다.
인덱스를 보면 변화를 알 수 있다.
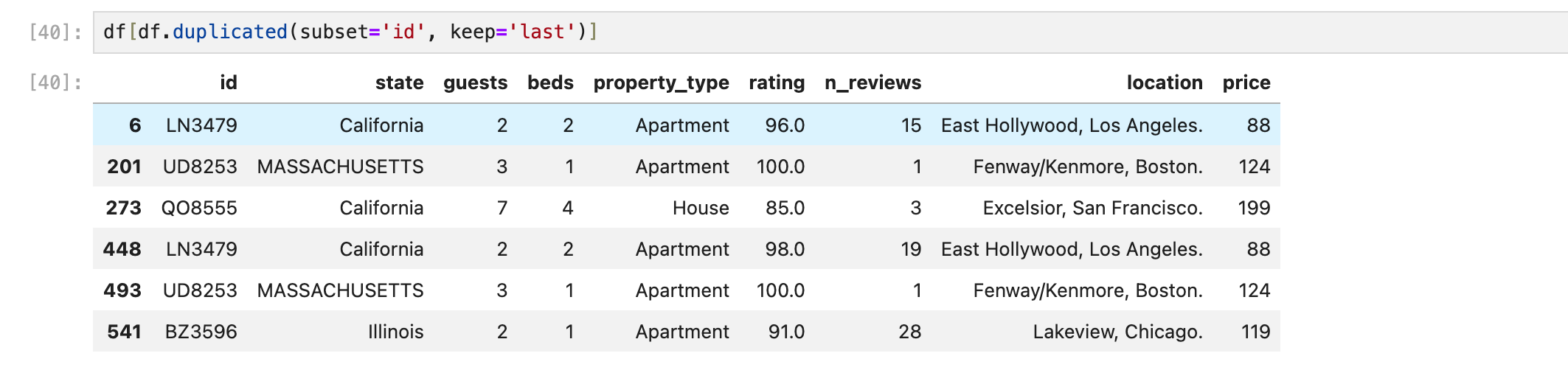
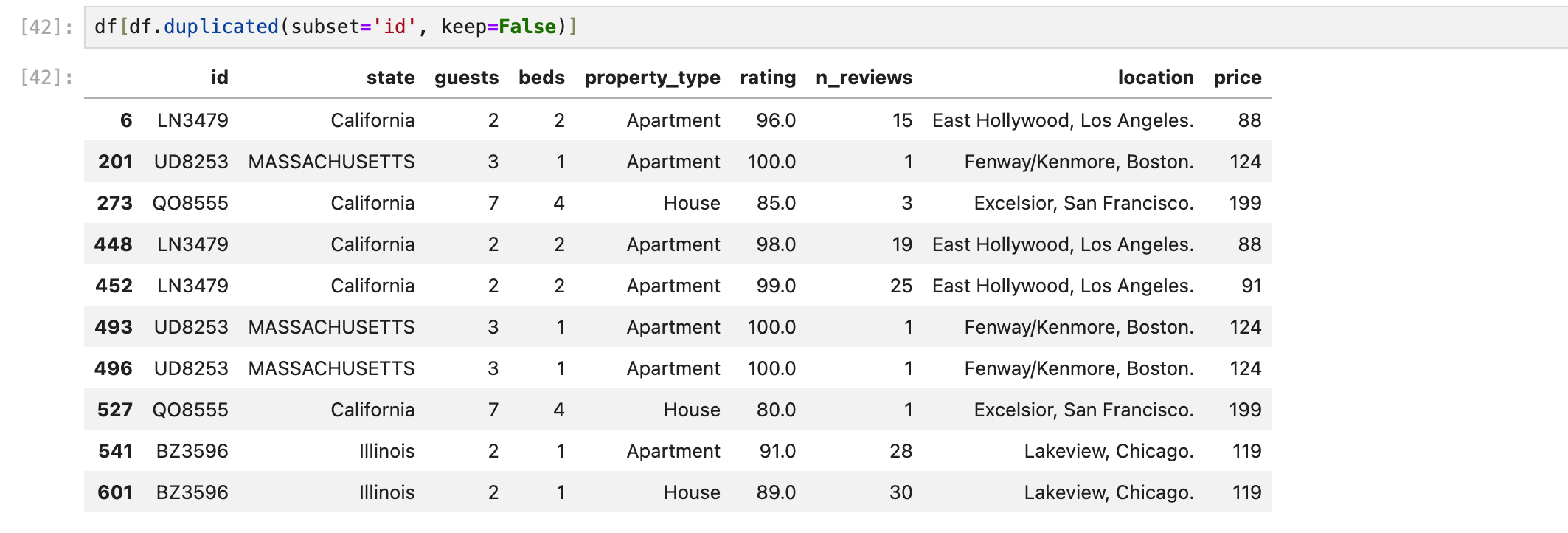
keep = False 를 쓰는 경우
first, last 상관 없이 중복되었다면 전부 가져온다.
중복값 처리하기
기본 데이터
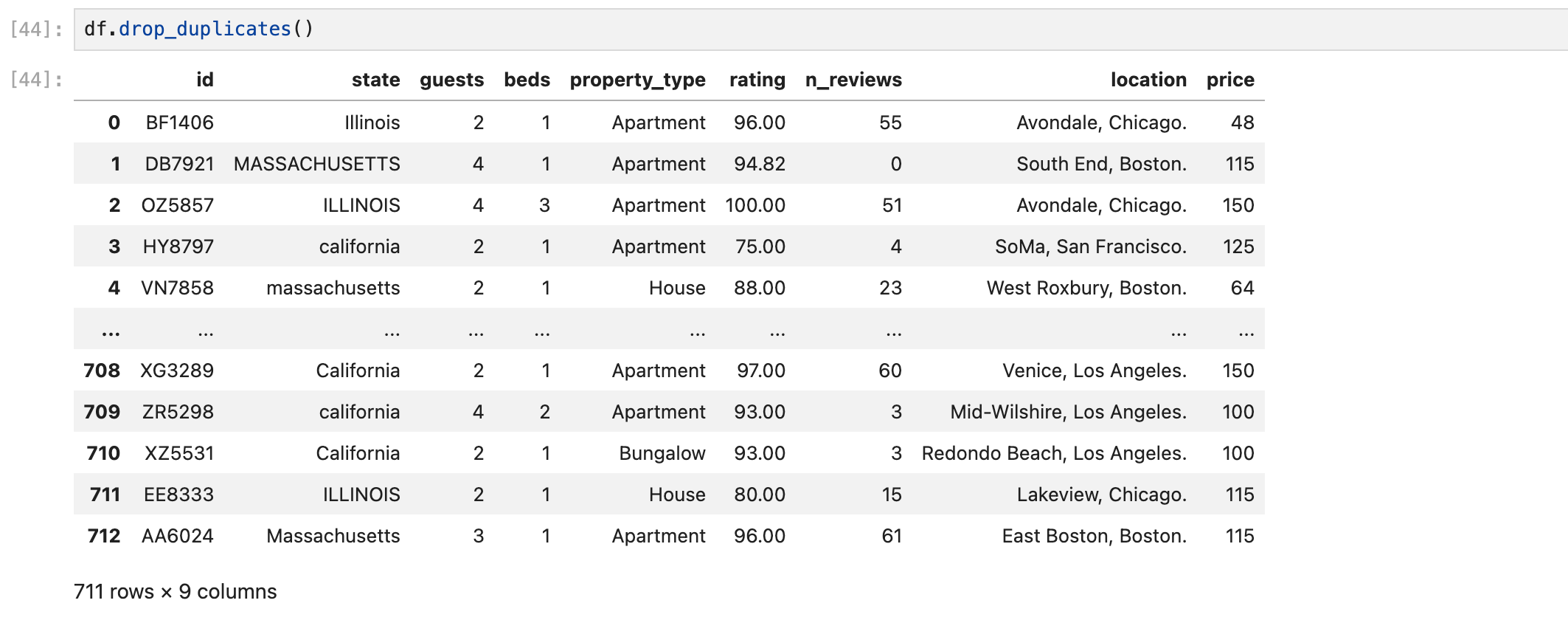
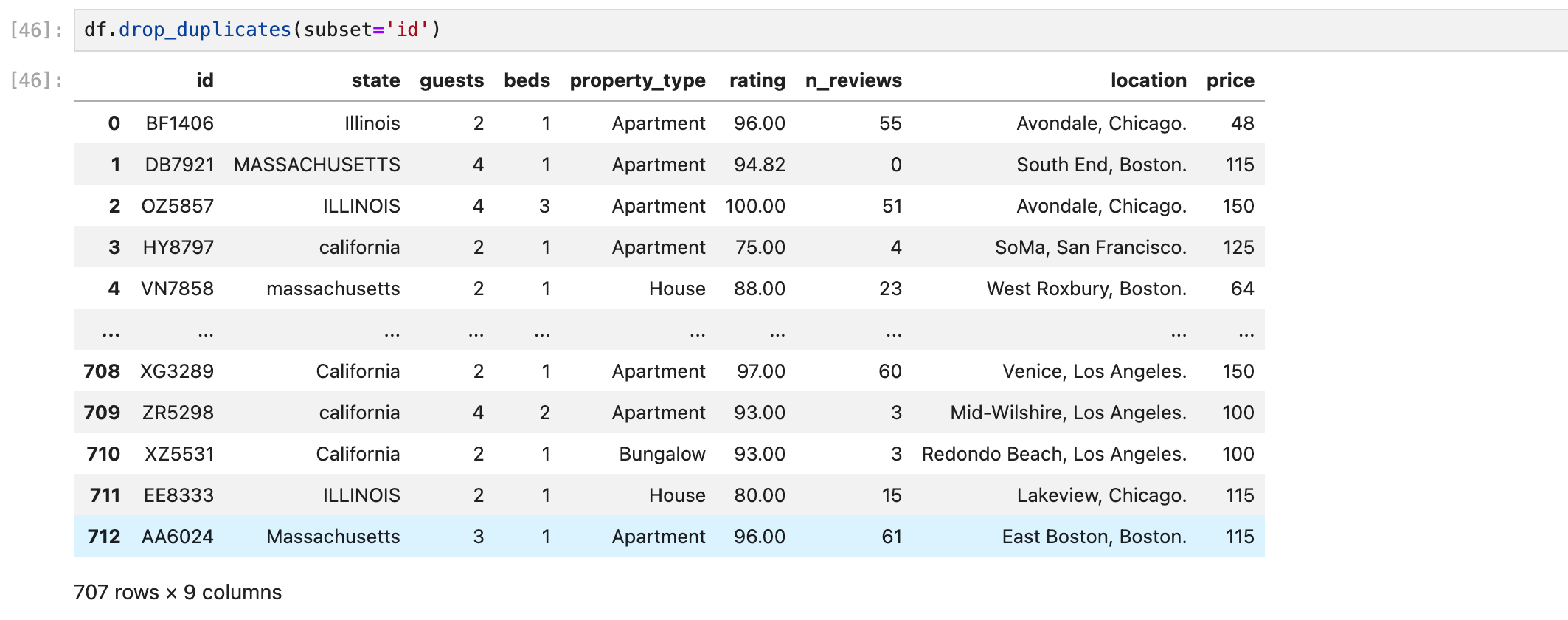
drop_duplicates()
모든 컬럼의 데이터가 중복되어야 중복값이라고 보고, 해당 row를 삭제한다.
당연히 중복값중 하나는 남겨놓고 삭제한다.
여기서도 전체 중복이 아닌 id컬럼 하나만 중복이어도 다 삭제하고 싶다면 subset 파라미터를 사용한다.
keep파라미터를 사용해서 마지막에 있는 중복값만 남기고 전부 삭제하는 것도 가능하다.
중복값을 제거한 데이터프레임을 저장해주고

정말로 삭제된 게 맞는지 확인한다.

실습 1
import pandas as pd
cellphone_df = pd.read_csv('data/cellphone.csv')
# 여기에 코드를 작성하세요.
cellphone_df = cellphone_df.drop_duplicates()
cellphone_df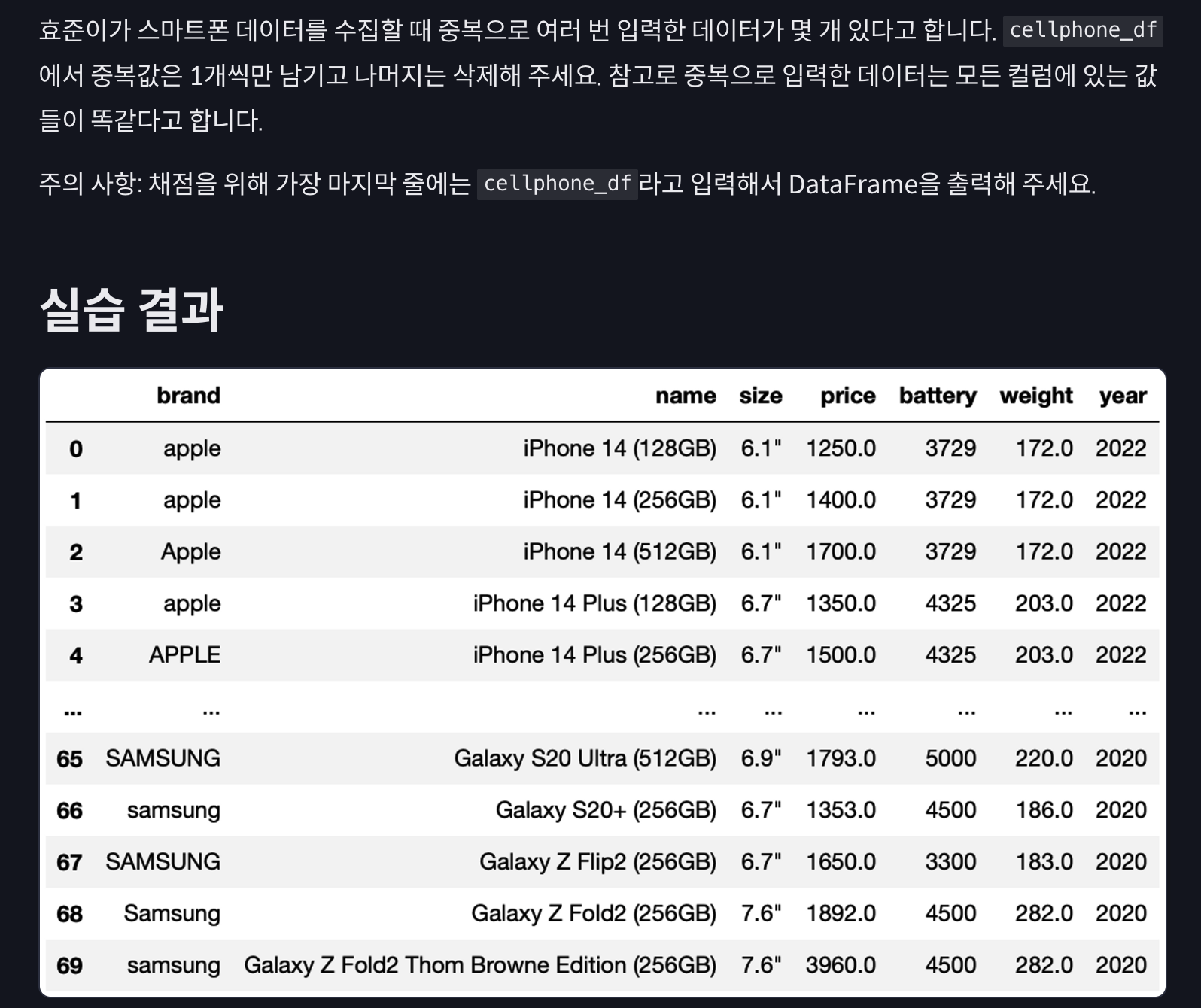
이상점 찾기
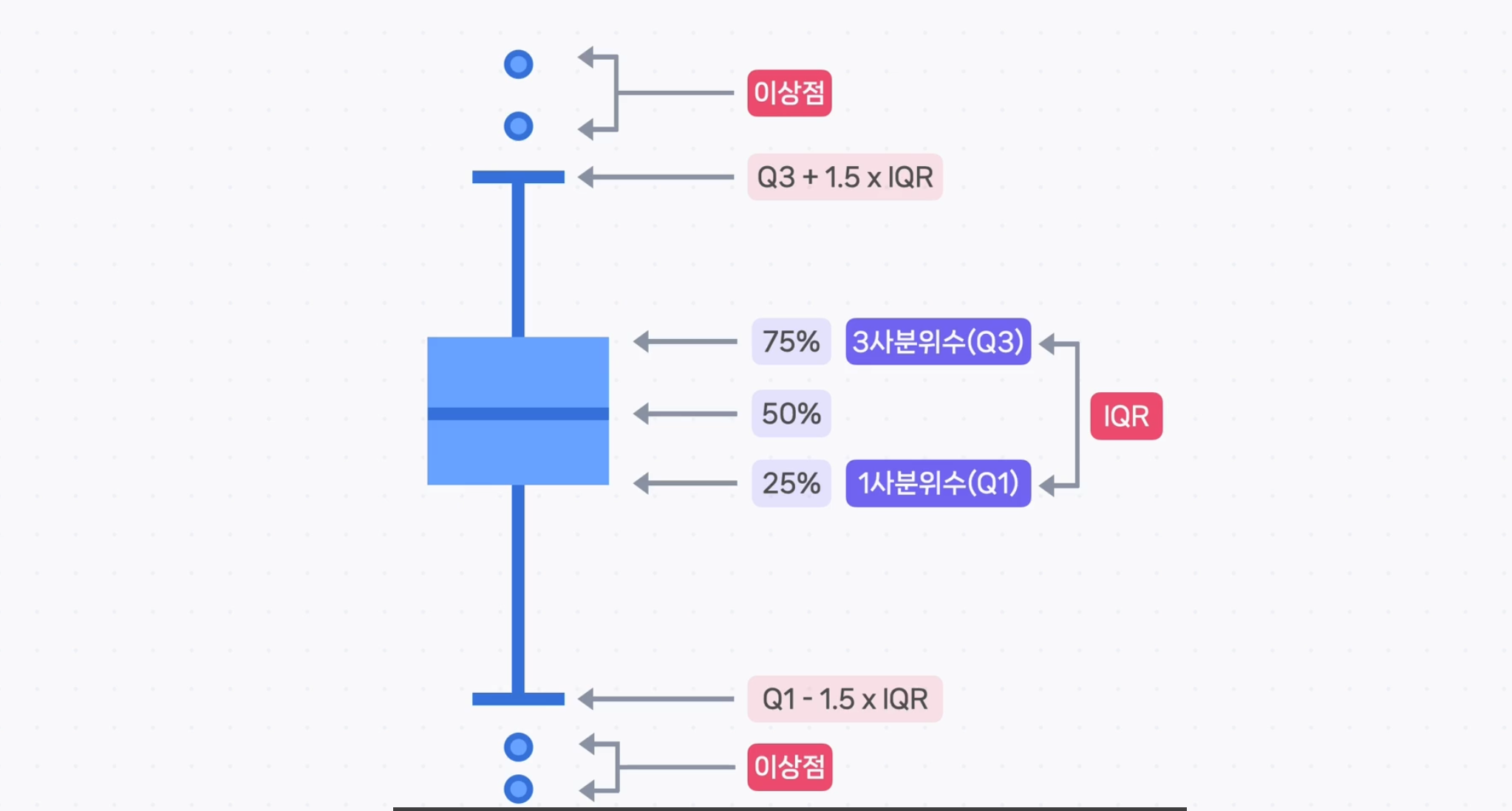
기본 데이터
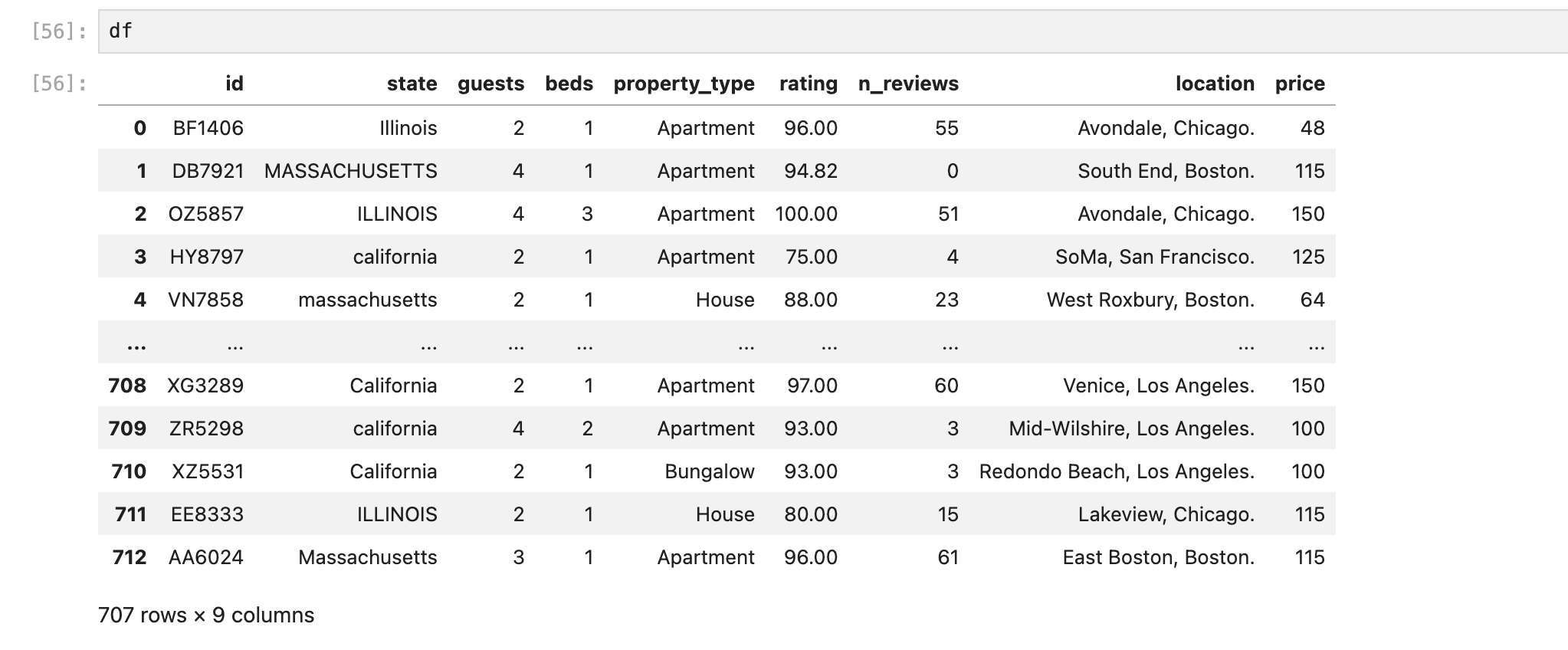
1사분위수와 3사분위수를 구하고 iqr을 구한다.

리밋을 구해 저장해준다.

불린 인덱싱을 하고나면 가격이 너무 저렴하거나 너무 비싼 이상점 데이터를 확인할 수 있다.
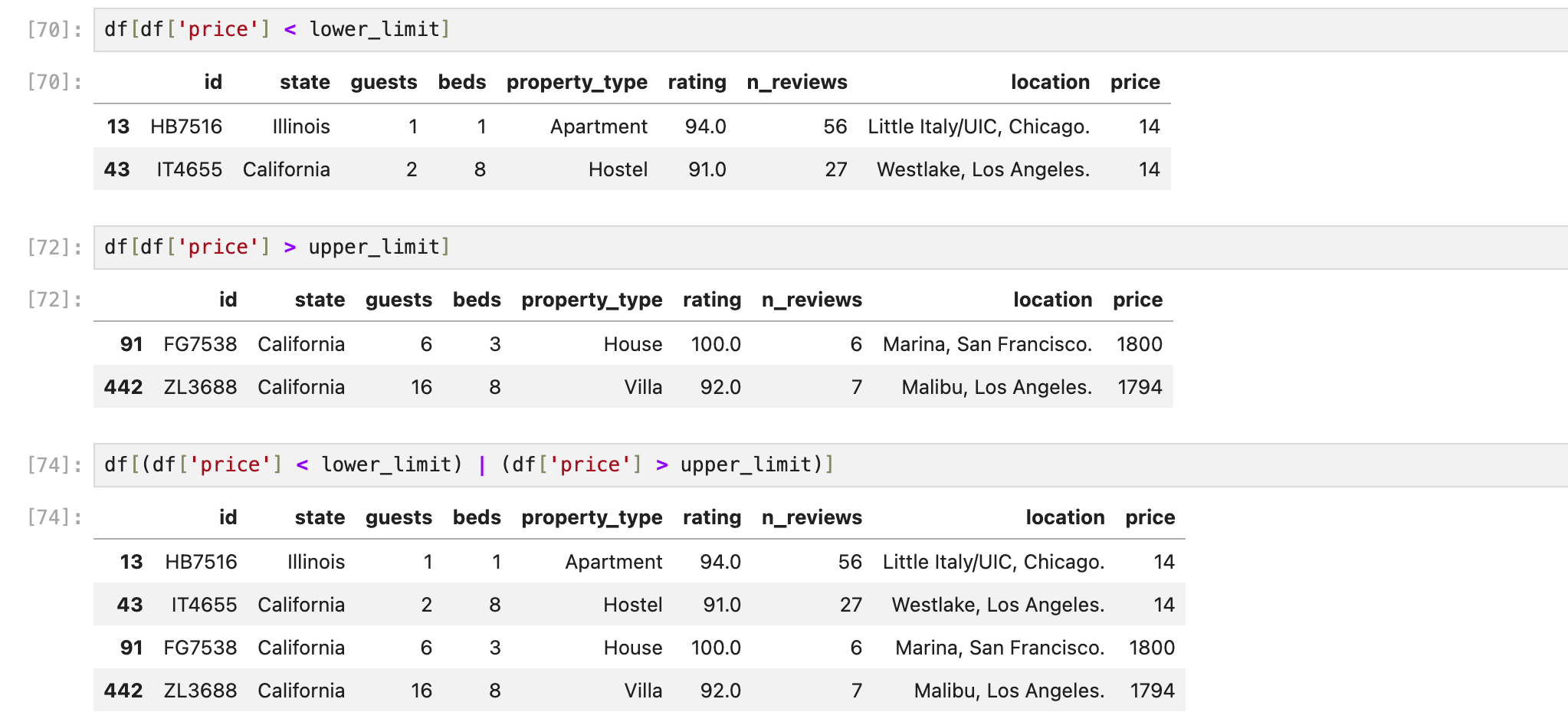
이상점 처리하기
1. 아무것도 하지 않기
2. 기준점보다 낮거나 높은 이상점의 값을 변경해준다.
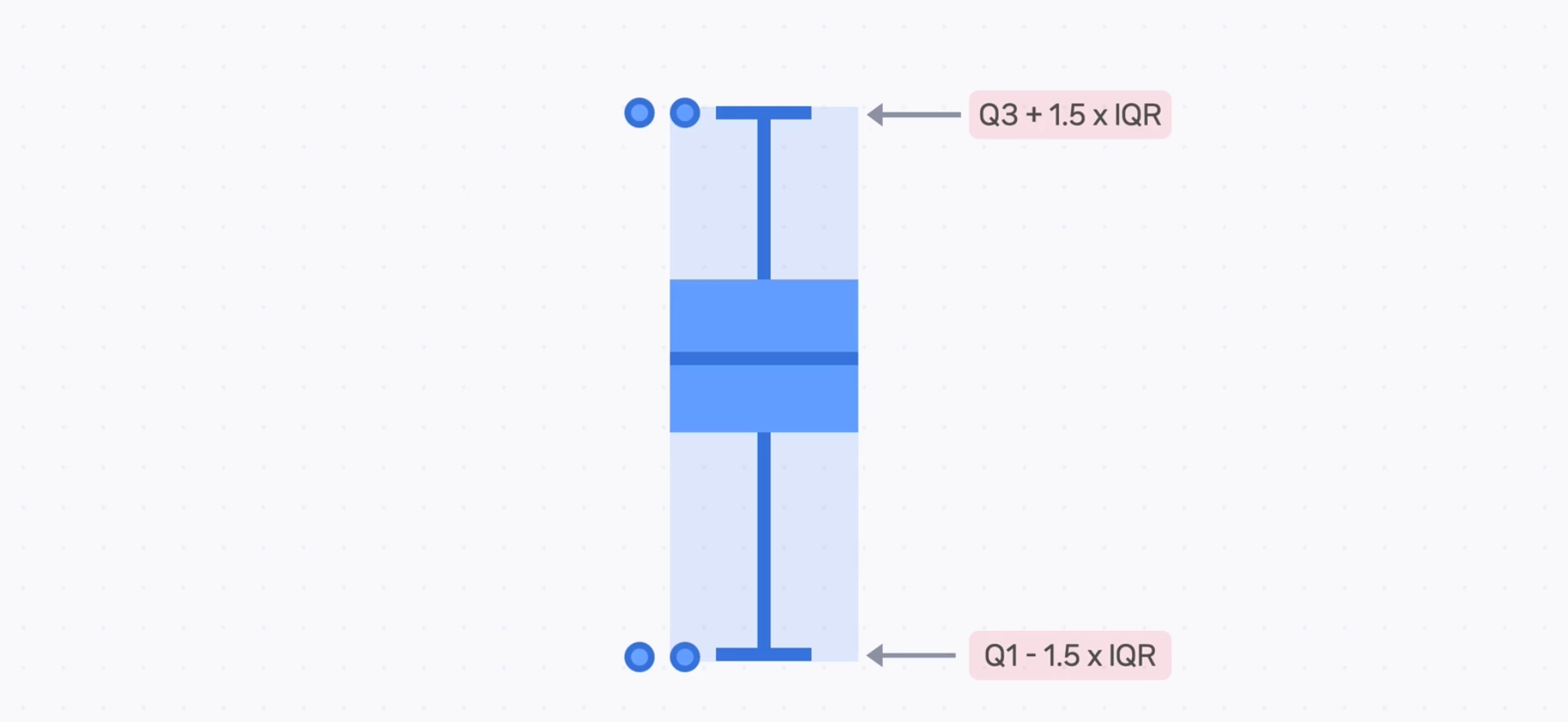
3. 이상점에 해당하는 데이터를 삭제한다. (오류가 확실할 때 / 지워도 영향이 없을 때)
기본 데이터
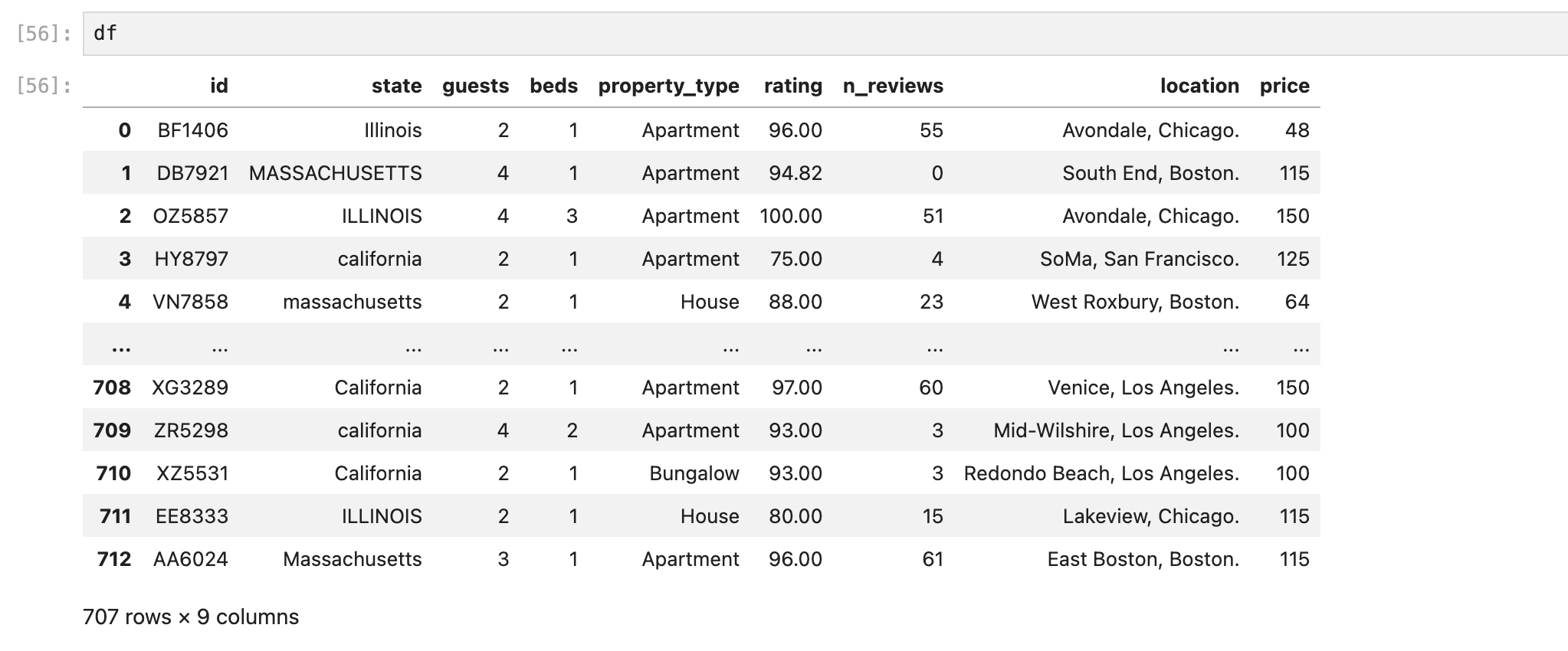
아까 만든 값으로 기준점 내에 있는 데이터들만 뽑아준다.

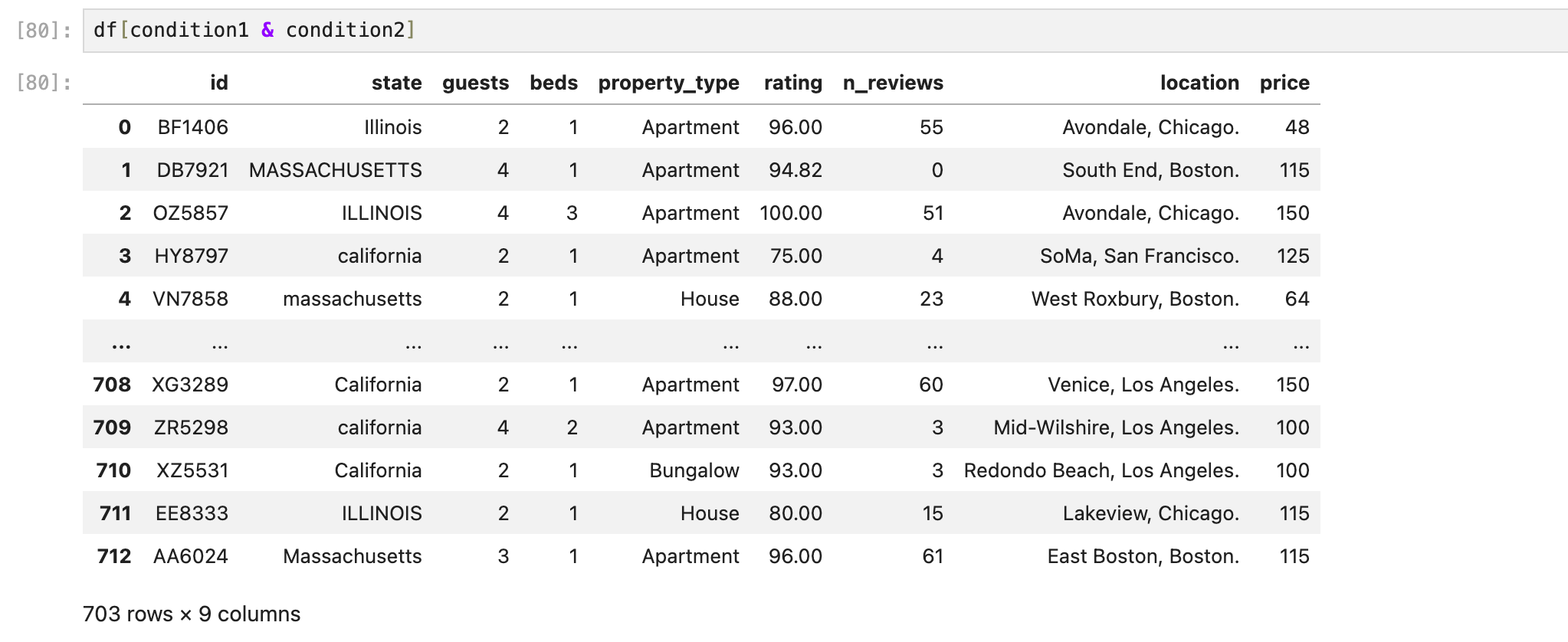
707개였던 로우가 이상점 데이터 4개를 제외하고 703개만 남았다.
실습 1
import pandas as pd
cellphone_df = pd.read_csv('data/cellphone.csv')
# 여기에 코드를 작성하세요.
q1 = cellphone_df['price'].quantile(0.25)
q3 = cellphone_df['price'].quantile(0.75)
iqr = q3 - q1
lower_limit = q1 - 1.5 * iqr
upper_limit = q3 + 1.5 * iqr
cellphone_df = cellphone_df[(cellphone_df['price'] >= lower_limit) &(cellphone_df['price'] <= upper_limit)]
cellphone_df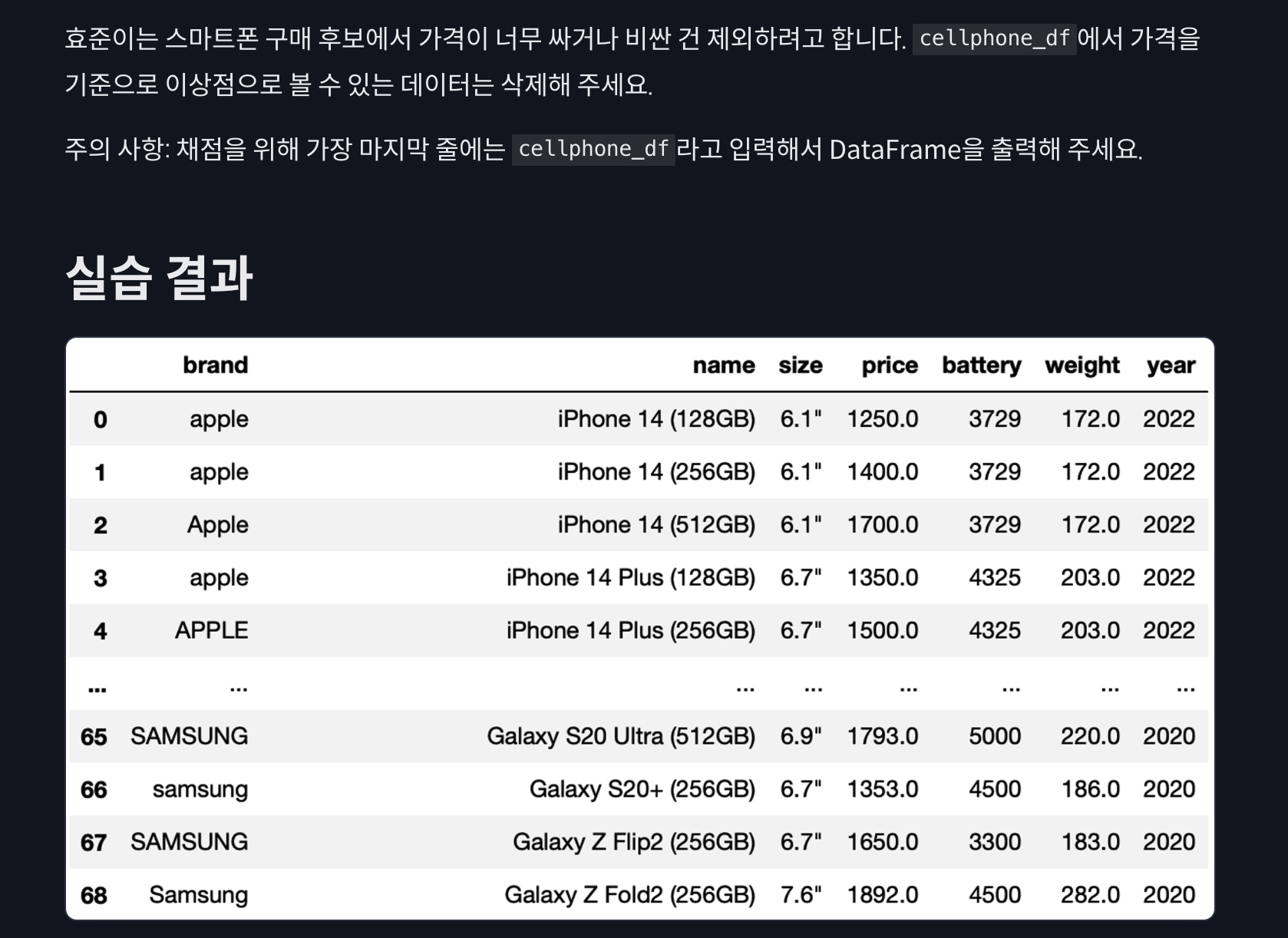
코드잇 14. 데이터 다듬기
'마케팅 > 데이터 분석' 카테고리의 다른 글
| [파이썬] 숫자 데이터 가공하기 (0) | 2025.03.14 |
|---|---|
| [파이썬] 문자 데이터 가공하기 (0) | 2025.03.13 |
| [파이썬] DataFrame 기본기 (0) | 2025.03.13 |
| [파이썬] seaborn (0) | 2025.03.13 |
| [파이썬] 통계 기본 상식과 그래프 (1) | 2025.03.09 |



